저번 시간에는 LinkedList 의 노드를 하나하나 파일에서 읽어오면서 삽입과 삭제를 진행했다. 노드를 하나하나 읽다보니 File I/O 가 읽는 만큼 생기게 됬고 상당히 비싼 연산으로 동작하게 됬다.
오늘은 이 LinkedList 를 일정 Block 단위로 묶어 한번에 읽어오고, 이에 대한 순회연산은 메모리 내부에서 진행하는 방식으로 최적화를 진행해보려고 한다.
기본구조
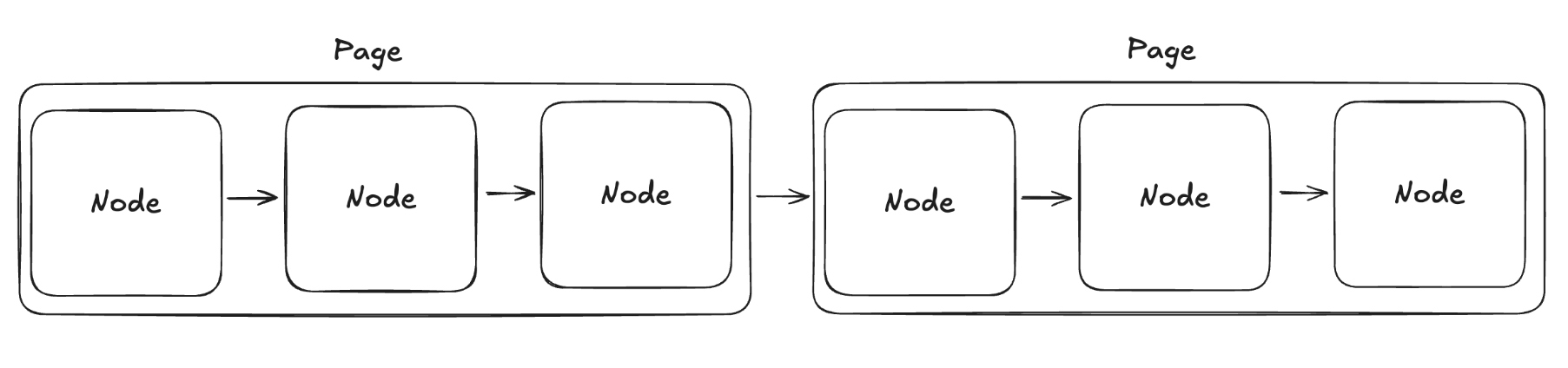
지난시간까지는 노드가 어디에 저장됬는지 offset 을 쫓아 이동했다면, 이제는 Page 를 연속적으로 쫓아 Page 가 어디에 저장됬는지를 찾게 될 것이다. 하나의 페이지사이즈가 4096 일때 이 페이지에 저장될 수 있는 16바이트 크기의 노드 개수는 256개이다. 그렇다면 우리가 페이징 시스템을 적용함으로써 얻을 수 있는 File I/O 의 이상적인 축소치는 아래와 같은 식이 될 것이다. 조금 더 수식적으로 정리해보자.
1. 기본 가정
* 페이지 크기 ($P_{size}$): 4096 bytes
* 노드 크기 ($N_{size}$): 16 bytes
* 기존 I/O 횟수 ($IO_{old}$): 10,000 번
2. 페이지 당 노드 수용량 ($C$)
한 페이지에 저장될 수 있는 노드의 개수는 아래와 같이 계산된다.
$$
C = \frac{P_{size}}{N_{size}} = \frac{4096}{16} = 256 \text{ (nodes/page)}
$$
3. I/O 감소 효율 계산
페이징 시스템을 적용했을 때 기대할 수 있는 파일 I/O 횟수($IO_{new}$)는 기존 횟수에 페이지 밀집도의 역수를 곱한 것과 같다.
$$
IO_{new} = IO_{old} \times \frac{1}{C}
$$
$$
IO_{new} = 10000 \times \frac{1}{256}
$$
$$
IO_{new} = 39.0625 \text{ (ops)}
$$
결론:
기존에 10,000번 발생하던 디스크 I/O는 페이징 기법을 통해 이론적으로 약 39.06번으로 감소하게 된다.
기존의 File I/O 가 10000 이고, 노드 사이즈는 16, 페이지 사이즈는 4086 인 경우로 가정해보자. 이 경우 페이지당 노드에 256개가 저장되게 되므로 아래와 같이 File/IO 를 줄일 수 있다.
구현
이제 구현부로 들어가보자. 저번 시간에 LinkedList 로 이미 File I/O 에 익숙해졌으므로 개념만 잡는다면 아주 쉽게 구현할 수 있을 것이다. 기본적으로 Page 의 offset 도 알아야 하고, Page 안의 Node 의 offset 도 알아야 할것이다. Page 안의 Node 는 이제부터 Slot 이라고 칭하겠다.
Node 구현
일단 첫번째로 저번시간과 마찬가지로 데이터를 저장할 Node 의 구현체부터 구현해보자. Node 는 uint32 타입의 값을 가지고, 다음 Slot 을 나타내는 NextSlot 과 다음 페이지를 가지는 NextPage 값을 가진다.
여기서 NextPage 를 왜 Node 가 들고있지? Page 가 들고 있어야 할거 같은데? 라는 의문이 들수도 있는데 이 설계의 경우 Page 는 단순히 노드를 관리하고 예제 수준에서의 복잡성 및 I/O 를 줄이기 위해 도입된 것이므로 Node 의 연속적인 탐색을 이어주기 위해 Node 에 NextPage 의 정보도 담도록 하였다. (만약, NextPage 가 조금 더 나은 설계라고 생각되시면 한번 혼자서 구현해보는것도 추천한다.)
type Node struct {
Value uint32 // 4 byte
NextPage uint32 // 4 byte
NextSlot uint16 // 2 byte
Tomb uint8 // 1 byte
_pad uint32 // 4 byte
}
Page 구현
이제 Page 에 대해 고민해보자. Page 는 어떠한 정보를 담고 있어야 할까? 사실상 지금 예시에서는 별다른 정보가 필요하지 않으니 얼마나 많은 노드가 있는지를 Length 라고 저장해보자. 이 값은 메타데이터이므로 Page 의 Header 로서 저장된다.
type PageHeader struct {
Length uint16
}
PageHeader 는 2byte 를 필요로 하므로 읽거나 쓸때 2byte 의 buffer 를 만들어주고 파일 시스템을 통해 쓰거나 읽어오면 된다. 이 부분은 이제 익숙하므로 바로 부가설명없이 코드로 적겠다.
func readPageHeader(f *os.File, pageID uint32) (PageHeader, error) {
offset := pageOffset(pageID)
if _, err := f.Seek(offset, io.SeekStart); err != nil {
return PageHeader{}, err
}
buf := make([]byte, PAGE_HEADER_SIZE)
if _, err := io.ReadFull(f, buf); err != nil {
return PageHeader{}, err
}
var ph PageHeader
ph.Length = Endian.Uint16(buf[0:2])
return ph, nil
}
func writePageHeader(f *os.File, pageID uint32, ph PageHeader) error {
offset := pageOffset(pageID)
if _, err := f.Seek(offset, io.SeekStart); err != nil {
return err
}
buf := make([]byte, PAGE_HEADER_SIZE)
Endian.PutUint16(buf[0:2], ph.Length)
_, err := f.Write(buf)
return err
}
다만 Page 의 경우 하나의 메소드가 하나 더 필요하다. Page 가 없을 경우 Used 를 0 으로 Page 를 하나 생성해주어야 한다. Used 를 0 으로 하고 페이지를 하나 생성해서 파일에 써주자.
// 새로운 빈 페이지를 파일에 생성
// - PageHeader(Used = 0) 으로 기록하고 나머지는 0 으로 채움
func initEmptyPage(f *os.File, pageID uint32) error {
offset := pageOffset(pageID)
if _, err := f.Seek(offset, io.SeekStart); err != nil {
return err
}
// 페이지 전체를 0 으로 채운다.
buf := make([]byte, PAGE_SIZE)
_, err := f.Write(buf)
return err
}
이제 Page 의 경우 기본적인 Interface 는 완성되었다. 그렇다면 저장소의 메타데이터인 Header 는 어떤 정보가 필요할까? Header 의 경우 이제는 읽어올때 Page 를 읽어오는 옵션이 생겼으므로HeadPage, TailPage 정보가 추가로 필요할 것이다.
Header 구현
type Header struct {
Magic [4]byte // Magic: 포맷 식별자 [4]byte{'L', 'L', 'S', 'T'}
Version uint16
PageSize uint16
PageCount uint32
HeadPage uint32
HeadSlot uint16
TailPage uint32
TailSlot uint16
Size uint64
}
우리가 파일을 읽고 쓸때 항상 첫번째 부분은 Header 이므로 Header 에 수정된 부분을 계속해서 업데이트 해주면 된다. Header 를 읽고 쓰는 부분 또한 코드로 적어보자.
func writeHeader(f *os.File, h *Header) error {
if _, err := f.Seek(0, io.SeekStart); err != nil {
return err
}
buf := make([]byte, 0, HEADER_SIZE)
buf = append(buf, h.Magic[:]...)
buf = Endian.AppendUint16(buf, h.Version)
buf = Endian.AppendUint16(buf, h.PageSize)
buf = Endian.AppendUint32(buf, h.PageCount)
buf = Endian.AppendUint32(buf, h.HeadPage)
buf = Endian.AppendUint16(buf, h.HeadSlot)
buf = Endian.AppendUint32(buf, h.TailPage)
buf = Endian.AppendUint16(buf, h.TailSlot)
buf = Endian.AppendUint64(buf, h.Size)
if _, err := f.Write(buf); err != nil {
return err
}
return nil
}
func readHeader(f *os.File, h *Header) error {
if _, err := f.Seek(0, io.SeekStart); err != nil {
return err
}
buf := make([]byte, HEADER_SIZE)
if _, err := io.ReadFull(f, buf); err != nil {
return err
}
copy(h.Magic[:], buf[0:4])
// Magic 검증
if h.Magic != Magic {
return ErrInvalidMagic
}
h.Version = Endian.Uint16(buf[4:6])
h.PageSize = Endian.Uint16(buf[6:8])
h.PageCount = Endian.Uint32(buf[8:12])
h.HeadPage = Endian.Uint32(buf[12:16])
h.HeadSlot = Endian.Uint16(buf[16:18])
h.TailPage = Endian.Uint32(buf[18:22])
h.TailSlot = Endian.Uint16(buf[22:24])
h.Size = Endian.Uint64(buf[24:32])
return nil
}
딱히 어려운 부분은 없고, 계속해서 사이즈 만큼의 buffer 를 만들고 파일에 적거나 읽는다. 이 부분만 알아두면 된다. 그렇다면 PagedLinkedList 도 저번시간에 만든 LinkedList 와 같이 기본적인 Interface 를 한번 만들어보자.
저장소 Interface 구현
type LinkedListStore interface {
Open(path string, truncate bool) (*Handle, error)
AppendTail(h *Handle, value uint32) error
DeleteFirstByValue(h *Handle, value uint32) (bool, error)
TraverseValues(h *Handle) ([]uint32, error)
TraverseValuesPhysical(h *Handle) ([]uint32, error)
Where(h *Handle, target uint32) (*Location, error)
Close(h *Handle) error
}
저번 챕터와 메소드는 거의 동일한데 TraverseValuesPhysical 가 추가되었다. TraverseValues 는 Page 를 메모리의 Buffer 로 읽어와 I/O 를 줄이는 버전이고, TraverseValuesPhysical 은 예전처럼 Node 의 Next 를 통해 전체 Node 를 I/O 로 순회하는 버전이다. 차이를 비교하기 위해 만들어 두었다.
읽는 것 보다 쓰는 것을 먼져 생각하면 조금 구조가 쉬우므로 쓸때 어떤 사항을 고려해서 구현해야 할지 생각해보자. 아마 아래와 같은 알고리즘으로 진행될 것이다.
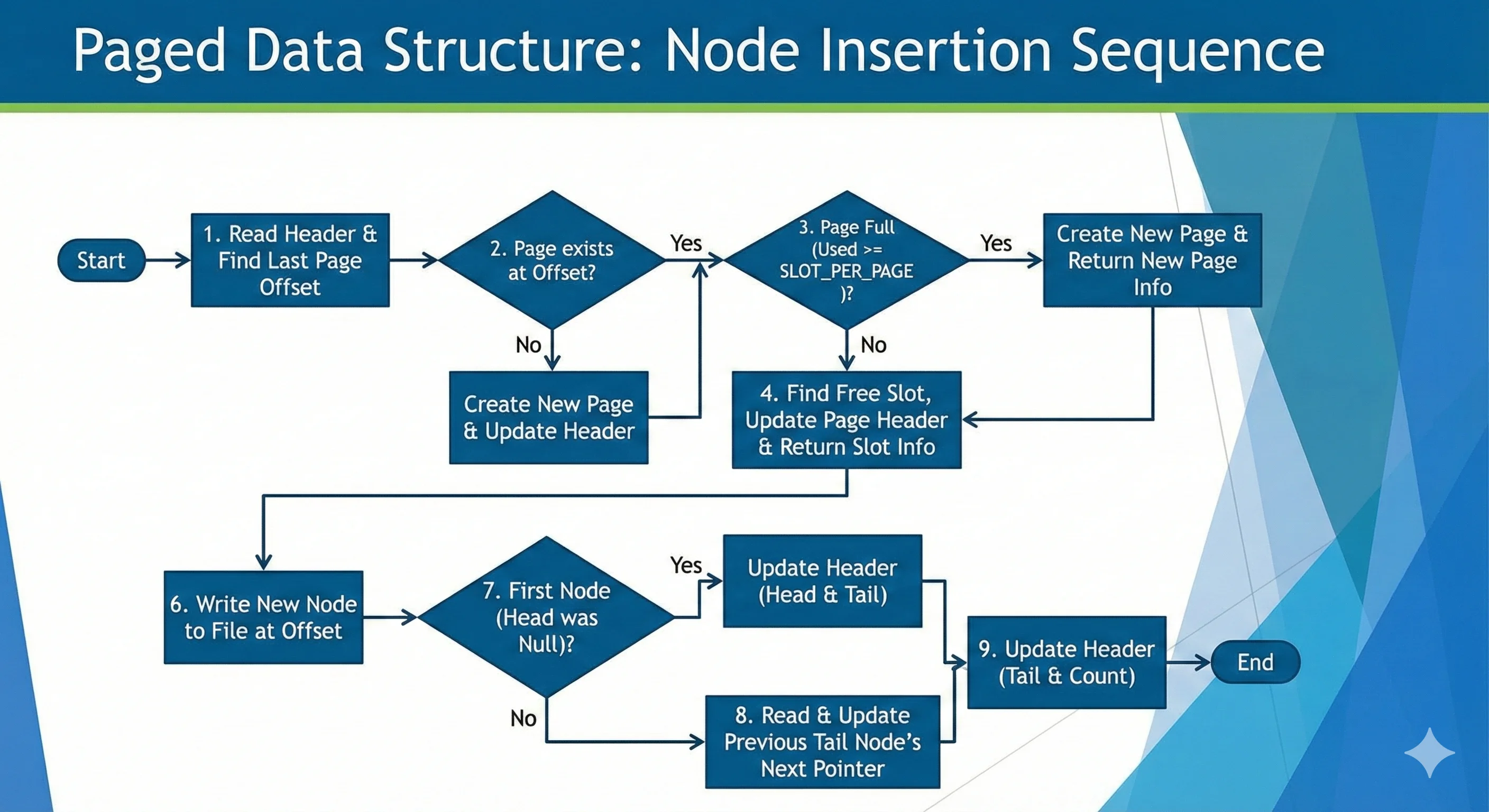
- 헤더를 읽어 파일에서
Page위치를 찾는다. - 만약 해당 위치에
Page가 없다면Page를 생성하고, 있다면 마지막Page정보를 리턴한다. (마지막인 이유는 여유가 있는 페이지는 마지막 페이지이기 때문이다.) - 해당 페이지에 노드를 쓸수 없는 경우 (PageHeader.Length >= SLOT_PER_PAGE) 에는 새롭게 페이지를 할당하여 리턴한다.
- 쓸수 있다면 노드를 어느 위치에 써야하는지 알려주고 Page 정보를 수정한뒤 리턴한다.
- 노드를 써야하는 위치로 Offset 을 이동시킨다.
- 새롭게 노드를 생성한 뒤 파일의 해당 위치에 노드를 작성한다.
- 기존 HeaderNode 가 없었다면 새 Node 로 갱신한다.
- 기존 TailNode 를 읽어와 기존 TailNode 의 Next 를 현재 노드로 갱신한다.
- 해더의 정보도 갱신한다.
사실 기존 메커니즘과 크게 다르지는 않다. 다만 새롭게 페이지를 할당하고, 노드에 이 정보를 갱신해야 하는 과정들이 추가되었다. 일단 큰 구현에 앞서 몇가지 먼져 짚고 넘어가야 할 부분이 있다. 우리가 Page 의 위치는 어떻게 추론할 수 있을까?
Page 가 연속적으로 쓰인다는 가정하에 Page 의 위치를 나타내는 ID 를 하나 0부터 시작하는 자연수의 sequence 로 부여 하고 페이지사이즈를 곱하면 해당 페이지의 offset 을 알수 있다.
$$PAGE_OFFSET = HEADER_SIZE + PAGE_ID \times PAGE_SIZE $$
코드로 구현해보면 아래와 같이 구현될 것이다.
// - 헤더 영역(HeaderSize) 이후에 페이지들이 연속적으로 저장된다고 가정
// - pageID=0 이면 header 바로 뒤에 오는 첫 페이지
func pageOffset(pageID uint32) int64 {
return int64(HEADER_SIZE) + int64(pageID)*PAGE_SIZE
}
이제 Page 의 위치를 구현하는 부분은 알았으니 Page 안에서 노드의 위치를 구현하는 부분을 계산해보자. Node 또한 Page offset 부터 Page 의 Header 사이즈만큼 이동한 다음 노드의 ID(Slot ID) 에 Node 의 크기를 곱한 부분부터 써주면 된다.
$$NODE_OFFSET = PAGE_OFFSET + PAGE_HEADER_SIZE + SLOT_ID \times NODE_SIZE $$
func writeSlot(f *os.File, pageID uint32, slotID uint16, node Node) error {
offset := pageOffset(pageID) + PAGE_HEADER_SIZE + SLOT_SIZE*int64(slotID)
if _, err := f.Seek(offset, io.SeekStart); err != nil {
return err
}
buf := make([]byte, SLOT_SIZE)
Endian.PutUint32(buf[0:4], node.Value)
Endian.PutUint32(buf[4:8], node.NextPage)
Endian.PutUint16(buf[8:10], node.NextSlot)
buf[10] = node.Tomb
Endian.PutUint32(buf[11:15], node._pad) // 의미없는 패딩값 (0 유지)
_, err := f.Write(buf)
return err
}
코드로 구현해보니 그다지 어렵지 않다. 그렇다면 이제 Node 를 쓰는 경우를 직접적으로 구현해보자.
// 새 슬롯을 할당하는 함수
// - 마지막 페이지가 존재하고 여유 슬롯이 있으면 그 페이지를 사용.
// - 마지막 페이지가 가득 찼으면 새 페이지를 생성하고 그 페이지의 0번 슬롯을 사용
// - Header 의 PageCount를 증가시킴
func allocateSlot(f *os.File, h *Header) (pageID uint32, slotIndex uint16, err error) {
if h.PageCount == 0 {
pageID = 0
if err = initEmptyPage(f, pageID); err != nil {
return
}
h.PageCount = 1
} else {
// 이미 페이지가 하나 이상 있으면, "마지막 페이지" 를 우선 사용
pageID = h.PageCount - 1
}
ph, err := readPageHeader(f, pageID)
if err != nil {
return
}
if int(ph.Length) >= SLOTS_PER_PAGE {
pageID = h.PageCount // 새 페이지 번호
if err = initEmptyPage(f, pageID); err != nil {
return
}
h.PageCount++
ph.Length = 0
}
slotIndex = ph.Length
ph.Length++
if err = writePageHeader(f, pageID, ph); err != nil {
return
}
return pageID, slotIndex, nil
}
func (s *PagedStore) AppendTail(handle *Handle, value uint32) error {
h, err := ensurePagedHeader(handle)
if err != nil {
return err
}
f := handle.File
pageID, slotIndex, err := allocateSlot(f, h)
if err != nil {
return err
}
slotOffset := pageOffset(pageID) + PAGE_HEADER_SIZE + SLOT_SIZE*int64(slotIndex)
if _, err := f.Seek(slotOffset, io.SeekStart); err != nil {
return err
}
newNode := &Node{
Value: value,
NextPage: NullPage,
NextSlot: NullSlot,
Tomb: 0,
_pad: 0,
}
if err := writeSlot(f, pageID, slotIndex, *newNode); err != nil {
return err
}
if h.HeadPage == NullPage {
h.HeadPage = pageID
h.HeadSlot = slotIndex
h.TailPage = pageID
h.TailSlot = slotIndex
h.Size++
return writeHeader(f, h)
}
tailNode, err := readSlot(f, h.TailPage, h.TailSlot)
if err != nil {
return err
}
tailNode.NextPage = pageID
tailNode.NextSlot = slotIndex
if err := writeSlot(f, h.TailPage, h.TailSlot, tailNode); err != nil {
return err
}
h.TailPage = pageID
h.TailSlot = slotIndex
h.Size++
return writeHeader(f, h)
}
위에서 설명한대로 페이지의 유/무에 따라 페이지를 생성하고 노드의 위치를 계산하는 allocateSlot 함수와 해당 offset 에 따라 노드를 작성하고 Header 를 갱신하는 부분을 작성해주면 된다.
읽기
이제 쓰기 부분은 마무리 되었고 읽기 부분을 작성해보자. 읽기 부분은 기존과 조금 다른게 Page 단위로 읽어와 이걸 메모리에 올려 Slot 은 메모리에서 순회해야 한다. 따라서 Page 의 정보를 담을 Buffer 가 필요하므로 PageBuffer 라는 구조체를 통해 Page 의 내용을 담도록 하겠다.
type PageBuffer struct {
pageID uint32 // 현재 버퍼가 담고 있는 페이지 ID
data []byte // len == PAGE_SIZE
valid bool // 아직 안 채워졌는지 여부
}
읽을때는 Page 를 읽어와서 Buffer 에 담고 첫번째 노드를 읽어온 후에 첫번째 노드 값의 NextSlot 정보를 통해 순회를 진행해주면 된다. 따라서 첫번째 노드를 읽어오는 메소드가 하나 필요하다.
func readSlotWithBuffer(f *os.File, pb *PageBuffer, pageID uint32, slotID uint16) (Node, error) {
// 1) 버퍼에 원하는 페이지가 없으면 페이지 전체를 한 번 읽어온다.
if !pb.valid || pb.pageID != pageID {
if err := pb.loadPage(f, pageID); err != nil {
return Node{}, err
}
}
// 2) 페이지 내에서 이 슬롯이 시작하는 오프셋 계산
// [PageHeader(2바이트)] [Slot0] [Slot1] ...
start := PAGE_HEADER_SIZE + int64(SLOT_SIZE)*int64(slotID)
// 3) buf[start : start+SLOT_SIZE] 부분만 잘라서 파싱
slotBytes := pb.data[start : start+SLOT_SIZE]
var node Node
node.Value = Endian.Uint32(slotBytes[0:4])
node.NextPage = Endian.Uint32(slotBytes[4:8])
node.NextSlot = Endian.Uint16(slotBytes[8:10])
node.Tomb = slotBytes[10]
node._pad = Endian.Uint32(slotBytes[11:15])
return node, nil
}
위와 같이 첫번째 노드를 읽어왔으면 그 정보를 통해 아래와 같이 순회해주면 Traverse 메소드가 손쉽게 완성된다.
func (s *PagedStore) Where(handle *Handle, target uint32) (*Location, error) {
h, err := ensurePagedHeader(handle)
if err != nil {
return nil, err
}
f := handle.File
page := h.HeadPage
slot := h.HeadSlot
var pb PageBuffer
for page != NullPage && slot != NullSlot {
node, err := readSlotWithBuffer(f, &pb, page, slot)
if err != nil {
return nil, err
}
if node.Tomb == 0 && node.Value == target {
return &Location{Page: page, Slot: slot}, nil
}
page = node.NextPage
slot = node.NextSlot
}
return nil, nil
}
Where 은 순회하는 부분에서 찾는 값이 있다면 위치를 리턴해주기만 하면된다.
비교
이제 기존 메소드와 함께 비교해보자. 약 10000 개의 노드를 순회했을때 발생되는 I/O 횟수를 계측한 것이다. Header 사이즈 등을 고려했을때 우리가 수식으로 계산했던 39와 비슷하게 나오는 것을 확인할 수 있다.
roach@User1:~/btree$ go run chapter02/compare/main.go
List built: Size=10000, PageCount=40
Naive traverse length: 10000
Naive I/O: Reads=10000, Writes=0, Seeks=10000
Buffered traverse length: 10000
Buffered I/O: Reads=40, Writes=0, Seeks=40
Buffered I/O Diff: Reads=-9960, Writes=0, Seeks=-9960
시간 차이는 얼마나 걸릴까? 조금 더 데이터를 늘려 1000000 건으로 테스트 해보자.
roach@User1:~/btree$ go run chapter02/compare/main.go
List built: Size=1000000, PageCount=3922
Naive traverse length: 1000000
Naive I/O: Reads=1000000, Writes=0, Seeks=1000000
Naive traverse time: 1.319998672s
Buffered traverse length: 1000000
Buffered I/O: Reads=3922, Writes=0, Seeks=3922
Buffered traverse time: 30.416243ms
Buffered I/O Diff: Reads=-996078, Writes=0, Seeks=-996078
Naive 의 경우 1.31 초 가량이 걸렸는데 Buffered 의 경우 0.03 초 가량밖에 안걸림을 확인할 수 있다. I/O 가 얼마나 비싼작업인지 내심 확인해 볼수 있는 지표이다.
마치며
이번 챕터에서는 Page 와 같은 블록단위로 관리하는 방법을 통해 메모리에 올려 빠르게 읽으며 I/O 를 줄이는 방법을 알아보았다. 다음시간에는 근본적으로 시간 복잡도를 줄이는 BinaryTree 를 이용해서 시간복잡도 까지 줄여보는 작업을 진행해보려고 한다.
💬 댓글 0