RDB 에서 큰 컬럼을 인덱스로 잡으면 안되는 이유
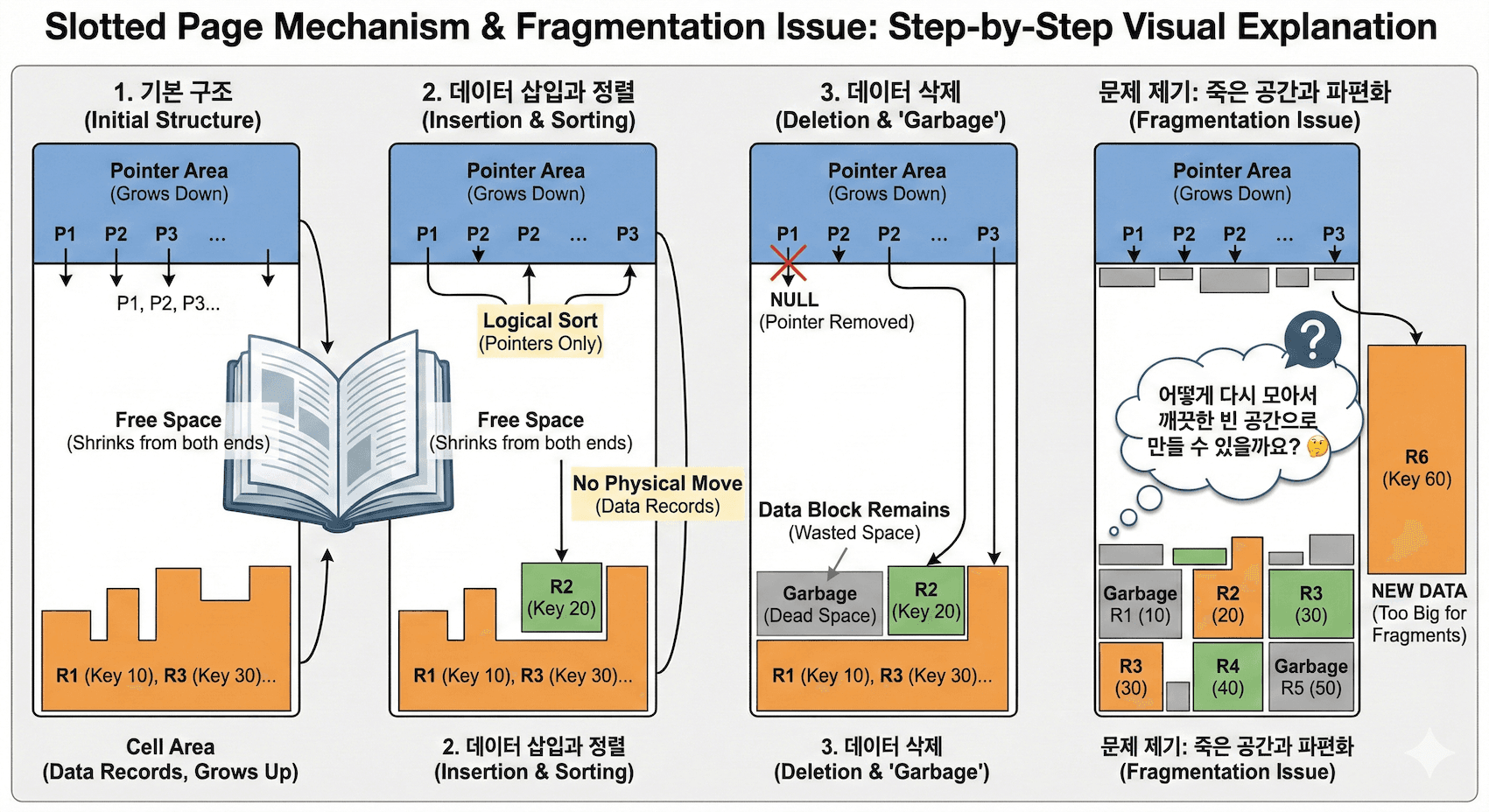
B-Tree 는 기본적으로 페이지 사이즈 와 저장할 수 있는 원소의 개수를 고정값으로 사용한다. 하지만 우리가 실제로 페이지에 저장하는 값은 가변적인 크기를 가지고 있기 때문에 필연적으로 물리적으로 저장해야할 개수가 다 차기도 전에 페이지가 넘치는 상황에 부딪히게 된다.

예를 들어 100KB 를 저장하는 페이지에 위와 같이 데이터를 저장한 상태이다. 여기서 데이터 40KB 짜리를 하나 더 넣으면 어떻게 될까? 물리적인 한계로 이 페이지에는 아마 저장할 수 없을 것이다. 그렇다면 어떻게 동작해야 할까?
Page Split
일단 페이지를 분할(Page Split) 하는 방법이 있다. 물리적인 페이지가 가득차게 되면 HDD 나 SDD 로부터 새로운 페이지를 할당 받아 데이터의 절반을 이주 시킵니다.
여기서 넘치는 것만 이주시키는 것이 아니라 반반해서 이주시키는 이유는 만약 Page 1 에 데이터가 또다시 들어오게 되는 경우 빈번하게 Page Split 이 일어날 확률이 높기 때문입니다.

예를 들어 40KB 를 또 삽입시켰다고 해봅시다. 이제 새로운 Page2 가 생기고 기존 Page 1 에서 5:5 로 나눠진 #2 가 Page 2 로 오게 됩니다. 즉 Page 1 에서 다음 데이터를 받기 위한 여유 공간들이 생기게 됩니다. 그리고 삭제/업데이트 등등이 되면서 더더욱 단편화가 많이 일어날 수도 있겠죠?

그렇기 때문에 인덱스를 리빌드 하는 과정이 필요합니다. 리빌드를 하게되면 어느정도 단편화가 해소됩니다. 만약에 너무 큰 데이터가 오면 어떻게 될까요? 예를 들면 95KB 같은 데이터가 들어오게 되는 경우 입니다. 그 경우에는 페이지에 하나의 원소밖에 저장되지 않게 되고, 이는 B-Tree 내부 페이지의 성능을 악화시키게 됩니다.
그래서 대부분의 데이터 베이스에서는 max_payload_size 이하인 것들을 페이지 내부에 저장하고 max_payload_size 를 초과하는 데이터의 경우에는 Overflow Page 에 저장하게 됩니다.
오버 플로우 페이지(Overflow Page)

너무 큰 데이터가 들어오면 위와 같이 페이지를 망가트리는 경우가 있게 될 수 있으므로 Linked List 를 통해서 원본 Page(Primary Page) 에서 link 를 통해 Overflow Page 로 갈수 있도록 연결시켜 둡니다. 이렇게 함으로써 페이지에는 최대한 정렬된 순서로 많은 원소가 들어갈 수 있게 됩니다.
마치며
결과적으로 메인 페이지(Primary Page)를 가볍게 유지하면, 하나의 페이지에 들어갈 수 있는 인덱스 키(Key)의 개수(Fanout)를 최대로 확보할 수 있습니다. 이는 거대한 데이터가 들어오더라도 B-Tree의 전체 트리 깊이(Tree Depth)가 깊어지는 것을 방지하며, 데이터베이스 검색 성능의 핵심인 '디스크 I/O 횟수'를 최소화하는 결정적인 역할을 합니다.
결론적으로 B-Tree는 데이터가 점진적으로 늘어나는 일반적인 상황은 **'페이지 분할(Page Split)'**을 통해 트리의 균형을 맞추며 확장하고, 트리의 구조 자체를 위협하는 비정상적으로 큰 데이터는 '오버플로우 페이지(Overflow Page)'로 격리하는 투트랙(Two-track) 전략을 통해 빠르고 안정적인 검색 성능을 유지한다고 볼 수 있습니다