
Slotted Page
데이터베이스와 관련된 기술을 보다보면 어떻게 데이터를 관리하고 저장하지? 특히 단편화(Fragmentation) 이 일어나는 것을 어떻게 통제하고 관리할까? 혹은 정렬된 자료구조 내부에서 데이터의 순서를 보존하기 위해 어떠한 행위들을 할까? 궁금해집니다. 오늘은 조금 더 데이터베이스 내부에 쓰이는 자료구조를 들여다보며 연관된 행위를 공부해보려고 합니다.
Fixed-size
데이터를 넣을때 저희가 넣는 데이터는 보통 사이즈가 안정해져있는 경우가 많습니다. 이를 variable-size records 라고 호칭하는데요. 이러한 데이터를 넣게 되면 가변 크기의 Page 를 읽거나 쓰는데 오버헤드가 생기거나 복잡해져 Fixed-size 의 Page 로 read, write 를 하는 방식이 대부분의 데이터베이스에서 이뤄집니다. (물론 variable-size 로 저장하는 방식도 있습니다)
Fixed-size 의 경우 좋아보이지만 아래와 같이 내부 단편화(Internal Fragementation) 문제가 발생합니다.
가변 길이 데이터를 저장하기 위해 페이지 내부를 N byte 단위의 **고정 크기 슬롯(또는 세그먼트)**으로 쪼개어 관리한다고 가정해 봅시다. 이때 M byte의 데이터를 저장한다면?
N - (M modulo N)byte 만큼의 공간이 낭비됩니다.
실제로 64 byte 를 N 으로 우리가 저장하려는 레코드의 사이즈 M 을 70 으로 잡으면 58 byte 만큼의 공간이 낭비됩니다. 대부분 실생활의 어플리케이션에서 저장되는 데이터들은 사이즈가 가변인 경우가 많으므로 내부 단편화가 지속적으로 생기게 됩니다.
이러한 문제를 어떻게 해결할 수 있을까요? 가장 간단한 방법으로는 부족한 공간을 기억하고 있다가 하나의 Page 로 치환할 정도의 공간이 나온다면 레코드를 여유가 되는 위치에 삽입하는 방법입니다. 하지만 이렇게 되면 실제로 저장된 레코드의 오프셋이 이동이 되어 메타데이터를 저장하고 있는 부분에 베타적인 Lock 을 거는 행위등이 발생 할 수 있고 꽤나 큰 오버헤드가 발생할 수 있습니다.
Slotted Page
이러한 문제를 해결하기 위해 Slotted Page 라는 개념이 도입되게 됩니다. Slotted Page 는 Pointer 영역과 Cell 영역을 나누어 관리합니다. (Page Header 영역도 있습니다)
Pointer Array
포인터 배열 영역은 실제 데이터가 저장된 위치(Offset) 을 가르키는 포인터의 배열입니다. 페이지의 앞부분인 Header 바로 뒷 부분에 위치합니다.
Postgresql 을 공부해보셨다면 이 개념을 Heap 에서 보셨을 거라 생각이 듭니다.
장점
왜 Pointer 영역이 존재할까요? 위에도 언급했지만 실제 저장된 Record 는 사이즈가 크기 때문에 재 정렬을 위한 이동과정에서 많은 오버헤드가 발생합니다. 하지만 실제 저장된 데이터는 가만히 있고, 참조하는 Pointer 의 위치만 바꾸게 되면 실제 데이터는 움직이지 않았지만 정렬 된 것 처럼 보이게 되는 것이죠.
또한 외부에서 실제 Actual Record 를 참조하게 된다면 실제 Record 가 저장된 offset 을 기억해야 합니다. 즉, 이 offset 관리에 또 overhead 가 발생됩니다. 이는 단편화가 발생한 지역을 청소하는 시점에 또 다른 오버헤드로 부가됩니다.
지금 처럼 Pointer 로 관리되는 구조에서는 외부에서는 Pointer 를 통해 간접 참조만 시행하면 됩니다. 즉, 실제 값의 Actual offset 을 참조할 일이 없어지는 것이죠.
단점
단점으로는 아래와 같이 크게 두가지가 존재합니다.
actual offset 을 참조하지 않고 pointer 를 통해 참조하므로 간접 참조 비용 발생
pointer array 를 저장하기 위한 추가 저장공간 필요
위와 같은 단점이 있지만 단점을 상쇄할만큼의 이점이 있어 Postgresql 과 같은 데이터베이스에서는 Pointer Array 를 운용합니다.
Cell 영역
Cell 영역은 페이지의 맨 뒷 부분부터 시작되어 앞쪽을 향해 실제로 채워지는 데이터입니다. Pointer 영역과 역방향으로 성장하는 이유는 둘이 같은 방향으로 성장하게되면 빈 공간이 여러 공간으로 쪼개질 수 있는데, 역방향으로 성장하게 되면 빈 공간은 이 두 영역의 중간 공간에만 생기기 때문입니다.
실제 데이터는 가변 크기(variable size) 의 레코드(Postgresql 의 경우 Tuple) 형태로 저장됩니다. Pointer 배열의 특정 Slot 이 이 Cell 의 시작지점을 가리키게 됩니다.
위에서 설명한대로 데이터가 가변적이다 보니 내부에 단편화 현상이 발생하게 됩니다. 가변 데이터의 특성상 이 구멍의 사이즈에 맞는 데이터가 들어오지 않는다면, 이 구멍은 영원히 채워지지 않은 상태로 존재하게 됩니다.
빈 공간 회수(Defragmentation / Compaction)
그래서 윈도우 사용자라면 익숙한 빈공간 회수를 위한 조각 모음(Compaction) 이 이뤄집니다. Cell 영역에 빈 공간이 많아지면 시스템에서 유효한 Cell 들을 모아 맨 끝쪽으로 재배치를 진행합니다. 이 과정에서 offset 이 변경되지만 외부에서는 pointer 를 통해 간접 참조하므로 문제가 발생하지 않습니다.
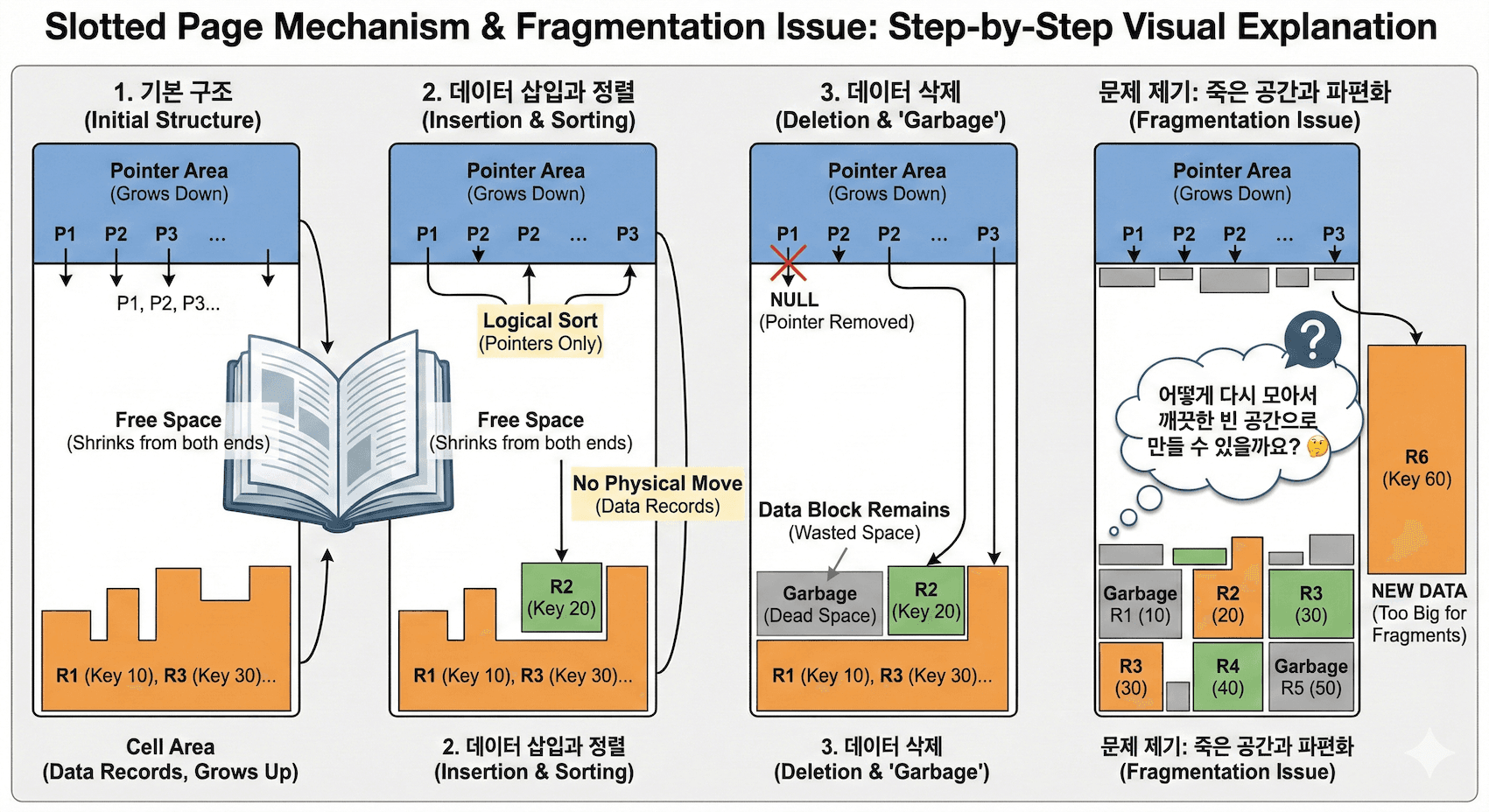
그림으로 이해하기

위 그림을 보면 첫번째 레코드를 삽입하면 전단 부분에 Slot (Pointer) 이 생성되고 실제 Record 가 저장된 Offset 을 가리키고 있는 것을 확인할 수 있습니다. 중간 부분은 Free Space 이고, Record 는 맨 뒷 부분에 기록됩니다.
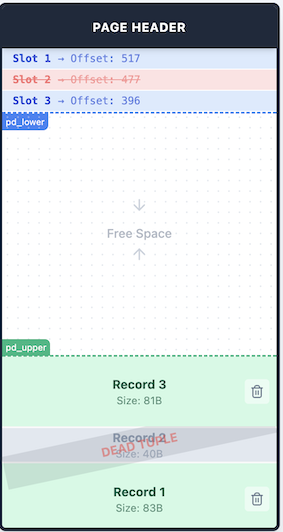
데이터를 추가할때 마다 중간 Free Space 가 줄어듭니다. Record 2 를 만약 위 그림 처럼 삭제한다면 어떨까요? Record 1 과 3 사이에 구멍(Hole) 이 생기며 단편화가 발생하게 됩니다. 낭비된 공간의 회수를 위해 빈공간 회수를 해봅시다.

빈 공간 회수를 하면 위에서 설명했던 것과 같이 유효한 Cell 들만 모아 끝쪽으로 재배치하며 유효하지 않은 부분에 대한 공간을 회수하게 됩니다.
마치며
확실히 Database Internals 를 읽으면서 그간 배웠던 Postgresql 에 대한 내용도 정리되는 것 같다. 그리고 Gemini 3.1 은 확실히 전작보다 시각 적인 부분에서 코딩을 잘한다. 위의 예시들은 전부 Gemini 에게 시각화를 시키며 학습하였다.