TF-IDF 와 BM25
최근 벡터 데이터베이스 설계와 구축이라는 책을 스터디하고 있는데, 거기서 TF-IDF 라는 개념을 배우게 되었다. 이전에 ES 를 쓰고 있어서 어림잡아 알고 있긴했는데, 이번 기회에 확실히 코드로 작성하며 숙달하고 이해하고 넘어가려고 한다. 오늘은 TF-IDF 의 의미를 알아보고 코드로 작성하며 이해해보자.
이 글에서 corpus 라는 용어를 많이 쓰게 될텐데 이글 내부에서는 우리가 가지고 있는 문서의 콜렉션으로 해석하면 된다.
* 이 글에서 용어(Term) 의 단위는 공백(뛰어쓰기) 기준으로 나눈다. 실제로는 사용하는 Tokenizer 에 따라 계산이 다르게 될 수 있다.
TF(Term Frequency)
TF 는 용어 그대로 문서(Document) 에 나타나는 단어의 빈도수를 의미한다. 기호로는 TF(t, d) 로 표기한다. 간단하게 t(Term) 이 얼마나 d(Document) 에 많이 등장하는가를 나타내는 함수이다.
TF(t, d) = t 가 d 에서 나타나는 빈도수 / d 의 모든 용어 수
아주 간단하게 위와 같이 계산된다. TF 의 분자값은 t 의 빈도수에 영향을 받고, 분모값은 용어의 총 개수의 영향을 받는다. 즉, 단어가 document 에서 많이 등장할수록 점수가 비례하여 높아지는 것이다.
파이썬 코드로 작성하면 아마 아래와 같이 작성해볼수 있을 것이다.
def tf(t: str, d: Document) -> float:
tokens = d.text.split()
frequency = tokens.count(t)
return frequency / len(tokens)
아주 심플하다. 그런데 코드를 작성하다보니 아래와 같은 의문이 든다.
왜 분모에
d 의 모든 용어 수라는 부분이 있을까? 그냥 단순하게 빈도수만 보면 안되나?
이렇게 분모에 단어수와 같은 제약을 두는 이유는 아래와 같다. 만약에 아래와 같은 문서 두개가 있다고 해보자.
문서 A : 사과 농장에서 자라는 사과는 정말 맛있어요.
문서 B : 사과하고 싶지만 영수는 사과를 할수 없었고, .... (1000 단어 가량의 문서 길이)
두 문서를 봤을때 "사과" 라고 검색한다고 하면 문서 A 는 TF(2, 6) 으로 나오고 문서 B 는 생략된 부분에 사과가 한개 더 등장해서 TF(3, 1000) 이 되었다고 해보자. 만약 빈도수만 본다면 문서 B 가 나오는 것이 정상이다.
하지만 빈도수가 높기만 한걸로 측정한다면 해당 용어가 그 문서내에서 얼마나 중요한 단어인지는 판단할수가 없다. A 문서에서는 6개의 단어중 2개인 1/3 이 "사과" 이므로 1000개 중에 3번 나오는 문서 B 에 비해 더 "사과" 가 중요한 비중을 차지하고 있다고 해석해볼 수 있다. 이것이 TF 의 분모에 문서 내에서 용어의 총 개수가 존재하는 이유이다.
IDF(Inverse Document Frequency)
IDF 는 흔한 단어는 가중치를 낮추고, corpus 내부에서 빈도수가 낮은 단어의 가중치를 올려주는 역할이다. 영어 문서를 예로 들자면 "the", "a" 와 같은 관사들은 주로 등장하므로 가중치가 낮아지고, "API" 와 같은 단어들은 개발문서에만 등장하므로 상대적으로 가중치가 높아진다. 가중치를 낮춰야 하므로 역함수의 형태를 뛰어 이번엔 아래와 같이 빈도수가 분모로 가게 된다.
IDF(t, D) = log (corpus 내부의 문서 개수 / t 를 포함하는 문서의 개수)
log 를 씌우는 이유는 스케일을 완만하게 만들기 때문이다. 직관적으로 와닿지 않을 수 있으니 아래와 같은 예시가 있다고 해보자.
the => 1000개의 문서 집합에서 1000번 등장
N / DF = 1quantum => 1000개의 문서 집합에서 1번 등장
N / df = 1000
위의 문서 셋에서 quantum 은 1000배나 중요하다고 판단된다. 즉, 과대평가가 되어 검색어의 결과의 하한(threshold) 를 설정하는데 문제가 될수도 있다. 그래서 log 를 씌우게 되면 quantum 의 중요도는 6.9가 되어 스케일이 줄어들게 된다.
AI 와 대화해보니 정보이론적 근거가 있다고 하긴 하는데.. 그 부분은 내 분야가 아니므로 한번 궁금하면 공부해보길 바란다. 아마 엔트로피 개념과 연관되어 있지 않을까 싶다.
IDF 는 파이썬으로 코드를 작성해보면 아래와 같이 작성해볼 수 있을 것이다.
def idf(t: str, corpus: list[Document]) -> float:
n = len(corpus)
df = sum(1 for doc in corpus if t in doc.text.split())
return math.log(n / df)
아직까지는 이해하기 쉽다. 이제 이 둘을 섞은 TF-IDF 에 대해서 알아보자.
TF-IDF
TF-IDF 는 더 단순하다 TF * IDF 를 한것이다. 실제로 아래 수식처럼 그냥 곱하기를 하면 된다.
TF-IDF(t, d, D) = TF(t, d) * IDF(t, D)
일단 이 수식이 뭔지 이해하기 전에 TF 와 IDF 를 한번만 더 짚고 넘어가보자.
TF: 이 용어(Term) 이 문서(d) 내부에서 얼마나 자주 등장하는가?
IDF: 이 용어가 corpus 내부에서 얼마나 희귀한가?
이 둘을 곱한 것이므로 빈도수가 높지만 흔한 단어(the 와 같은) 들은 IDF 점수가 낮으므로 상대적으로 낮은 점수를 받게 될 수 있고, 빈도수가 낮지만 희귀한 단어들은 IDF 점수가 높으므로 상대적으로 높은 점수를 받을 수 있게 된다.
즉, corpus 내부에서 내가 검색하려는 용어(t) 에 대해 중요도와 빈도수를 어느정도 조합하여 검색하는 것이라 보면 된다. 하지만 위의 수식을 보면 알듯이 TF(t, d) 가 압도적으로 높다면 아무리 희귀하지 않다고 해도 점수가 높게 측정될 수도 있다.
이렇게 되면 상관없는 문서들이 나오게 될 수 있으므로 별도의 가중치를 두어야 하나? 아니면 상한(maximum threshold) 를 두어서 막아야 하나? 등의 고민을 해볼만 하다. 하지만 이런 방법론을 연구하고 실험하는 것 또한 어렵다. 이를 해결하기 위한 유명한 솔루션은 BM25 라는 방식을 이용하는 거라고 한다.
BM25
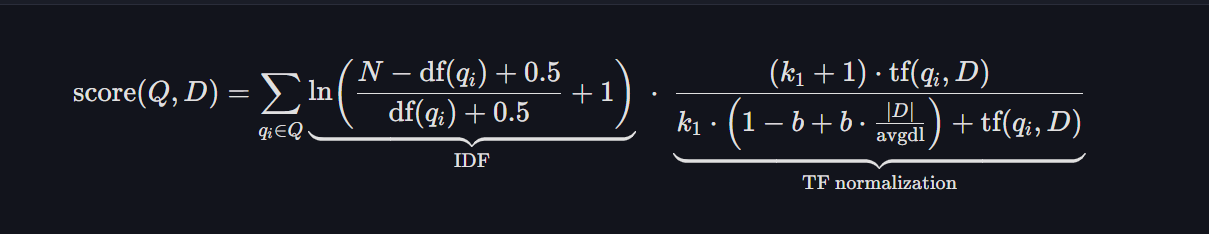
BM25 의 수식은 위와 같다. 엄청 복잡해 보이지만 복잡하게 적은 것일 뿐 하나하나 뜯어보면 그렇게 어렵지는 않다.
Q | 검색하려는 쿼리의 토큰 으로 분리한 집합 ({q_1, q_2, q_3, ...}) |
|---|---|
D | 점수를 매기려는 개별 문서 |
TF(q_i, D) | Term Frequency 위에서 설명했으니 여기에선 별도로 안함 |
|D| | 문서 D 의 총 토큰 수(긴 문서는 너무 커지니 보정 필요) |
avgdl | 전체 corpus 의 평균 토큰 수 |
N | corpus 내부의 전체 문서 수 |
df(q_i) | 토큰 q_i 가 등장하는 문서의 수 |
k_1 | TF 의 포화속도를 결정하는 값(튜닝해야 하는 값임) |
여기서 대부분은 우리가 이해할 수 있지만 k_1 은 새롭게 보는 개념이다. 이는 포화를 위한 계수인데 보통 1.2 ~ 2.0 사이의 값을 채택한다고 한다.
K1 (term frequency saturation)
score = (k_1 + 1) * tf / (k_1 + tf)
위와 같은 수식일때 tf 가 커지면 커질수록 분자/분모가 모두 커지므로 일정값에 수렴하게 된다. 예를 들어, k_1 이 1 이라고 해보면 아래와 같은 tf 값을 대입해가며 나오는 값을 확인해볼 수 있다.
tf = 1 → 2·1/(1+1) = 1.00
tf = 2 → 2·2/(2+1) = 1.33 (+0.33)
tf = 3 → 2·3/(3+1) = 1.50 (+0.17)
tf = 5 → 2·5/(5+1) = 1.67 (+0.17 for 2 steps)
tf = 100 → 2·100/101 = 1.98 (+0.31 for 95 steps)
위의 결과를 보면 1 -> 2 로 갈때는 0.33 이나 늘었지만 5 -> 100 일때는 0.31 밖에 오르지 않았다. 즉, 분자가 아무리 커져도 분모도 커지므로 점점 영향력이 약해지는 것이다. 즉, k_1 의 값이 높아지면 높아질수록 느리게 포화되고 상한선 또한 높아진다.
그래프로 동일한 corpus 에서 k_1 = 1.0 일때와 k_1 = 3.0 일때를 그래프로 비교해보자.
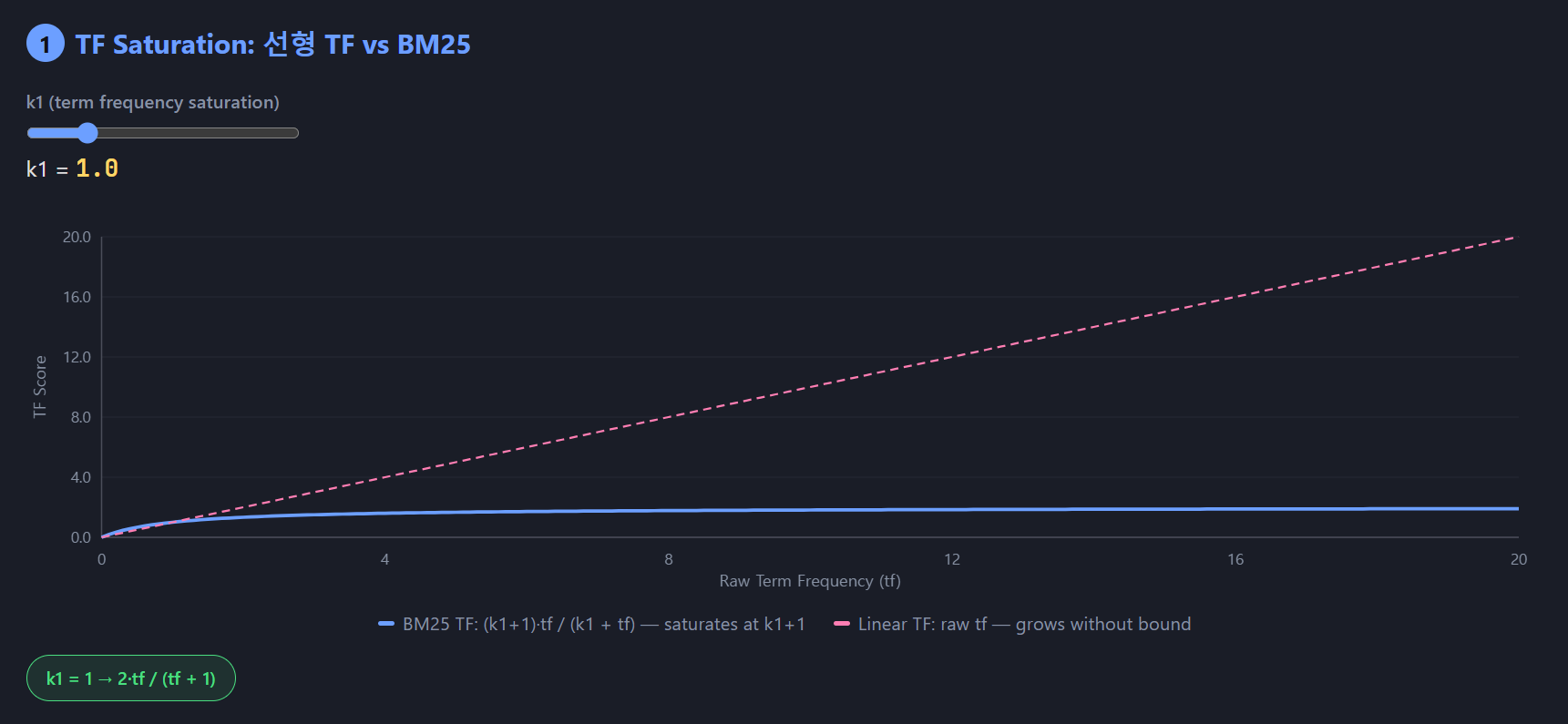
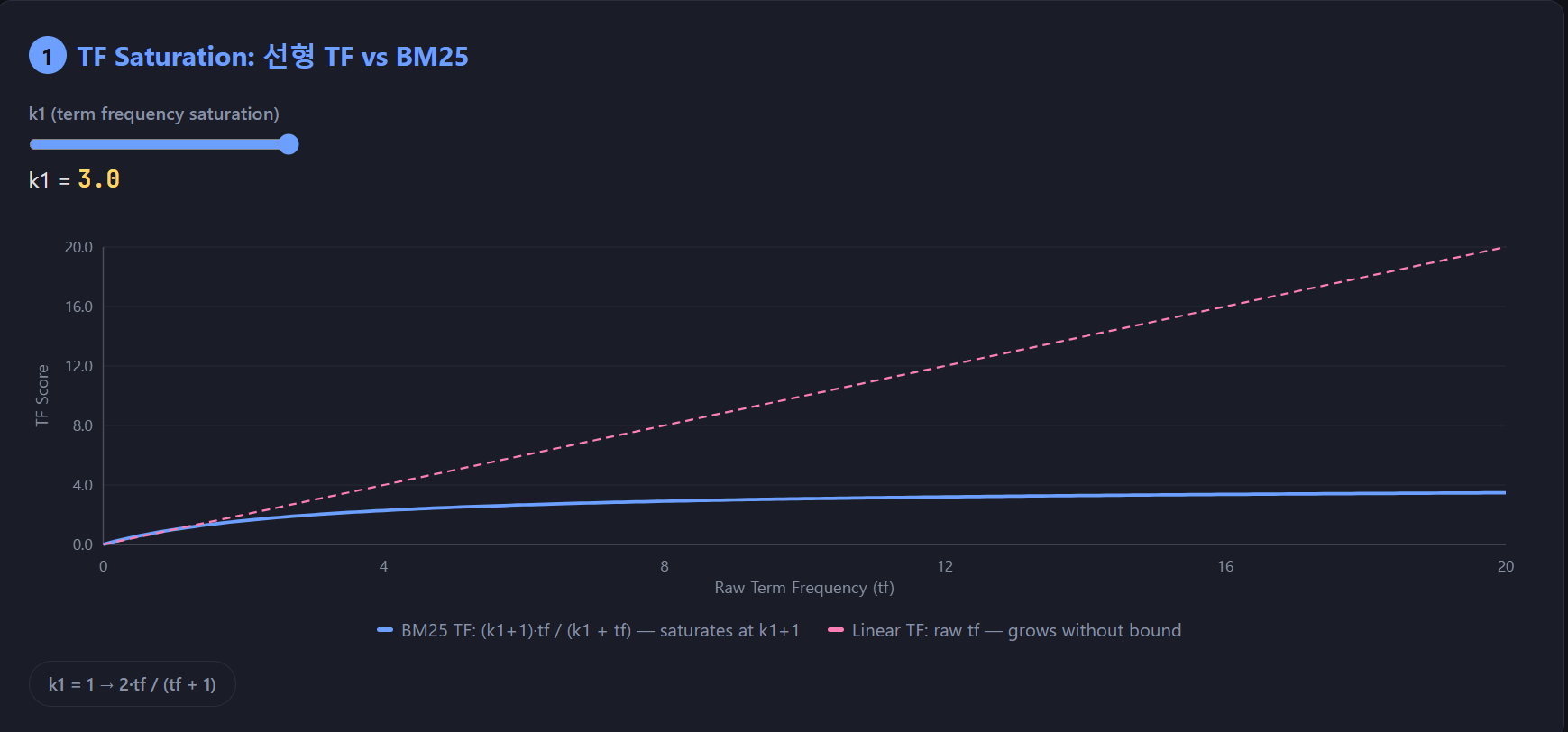
위 그래프를 보면 k_1 이 3.0 일때 점수자체가 좀 더 높은것을 알수 있고 일정스코어 이상에 수렴하기 까지 걸리는 시간도 오래걸림을 알 수 있다. 조금 더 해석을 해보자면 TF 점수를 얼마나 믿을 것 인가? 로도 해석해 볼 수 있다.
b (length normalization parameter)
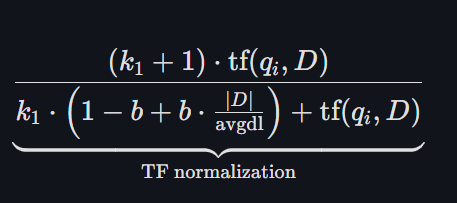
b 또한 가중치인데요. 여기서는 (1 - b + b * |d|/avgdl) 에만 집중하면 조금 더 쉽게 이해할 수 있습니다. 일단 |D| * avgdl 을 먼져 해석해보면 이 문서가 평균적으로 얼마나 긴가? 를 나타내는 값으로 볼 수 있습니다. 이 값이 분모에 있으므로 문서가 길면 길수록 점수가 낮아지는 구조가 됩니다. 즉, 문서가 길면 어떤 단어가 나올 확률도 높다고 생각해서 정규화를 해준다고 생각하면 됩니다.
그러면 수식을 쉽게 이해하기 위해 b 가 0 일때를 가정해보겠습니다. b 가 0 이면 1 - 0 + 0 * |d|/avgdl 이 되므로 사실상 문서 문서길이에 대한 패널티를 안보겠다는 것과 같습니다. 반대로 1일때는 어떨까요? 1 - 1 + 1 * |d|/avgdl 이 되므로 "문서 길이에 대한 패널티만 적용하겠다" 와 같습니다. 즉, 1 에 가까우면 가까울수록 문서 길이에 비례한 점수 페널티가 커집니다.
이것도 그래프로 한번 살펴보도록 하겠습니다.
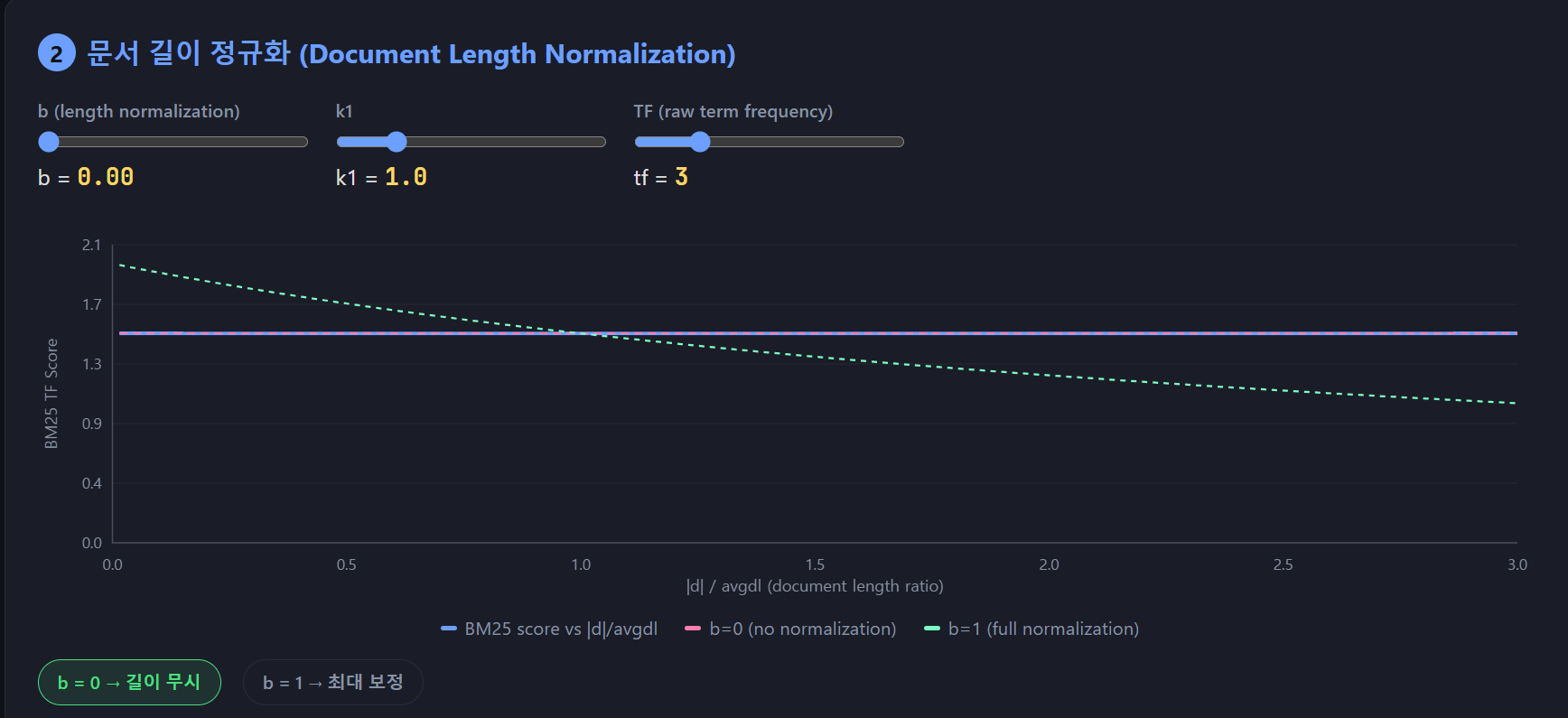
b 가 0 일때는 |d|/avgdl 에 대한 패널티가 없는 상태입니다. 따라서 x 축의 값인 |d| / avgdl 이 올라가도 그래프가 변하지 않습니다.
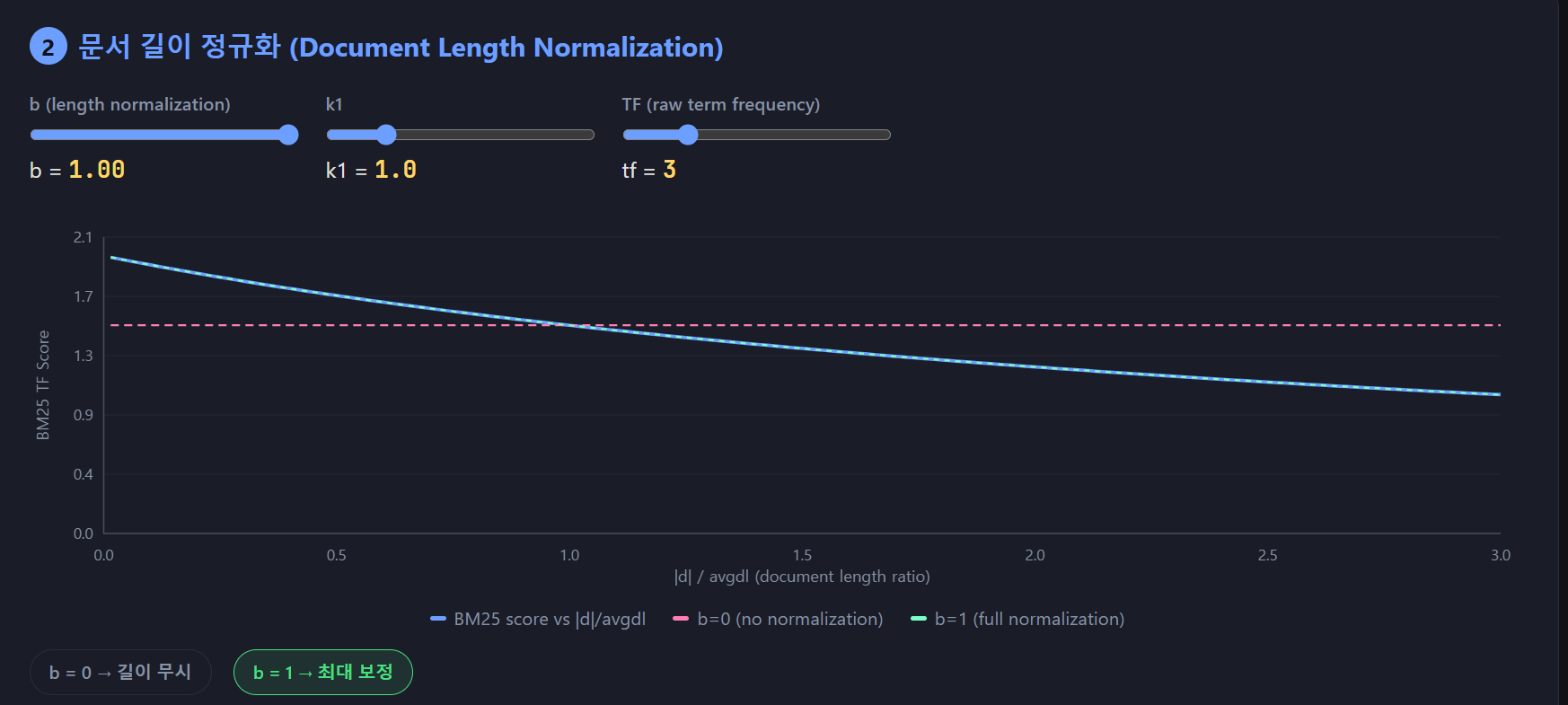
b 가 1 일때는 |d| / avgdl 이 커지면 커질수록 우하향 하는 모습을 확인할 수 있습니다. 즉, 분모의 값이 커지므로 점수가 빠르게 내려가는 것을 확인할 수 있습니다.
정리
BM25 수식쪽에와서 살짝 복잡해진 부분은 있지만 하나하나 뜯어봤을때 아래와 같은 부분들을 커버한다고 이해하면 될 것 같습니다.
TF saturation 은 TF 일정 단어가 반복되는 스팸문서에 대한 페널티를 적용합니다.
Length Normalization 은 긴 문서일수록 분모가 커져서 점수를 깎아 긴 문서에 대한 보정을 적용합니다.
IDF 희귀한 단어일수록 가중치를 줍니다
Openclaw 나 LLM 메모리에도 적용해 볼수 있을까? 근데 대화내에서 문서를 어떤 단위로 잡아야 할지.. 뭐 이런것들이 고민이라 쉽지 않을것 같다.