[짧은 글] 1024, 2048, 4096 크기를 지키는게 왜 중요할까?
![[짧은 글] 1024, 2048, 4096 크기를 지키는게 왜 중요할까?](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1766904351847%2F12a92d1b-f332-465d-a580-192582808007.png&w=3840&q=75)
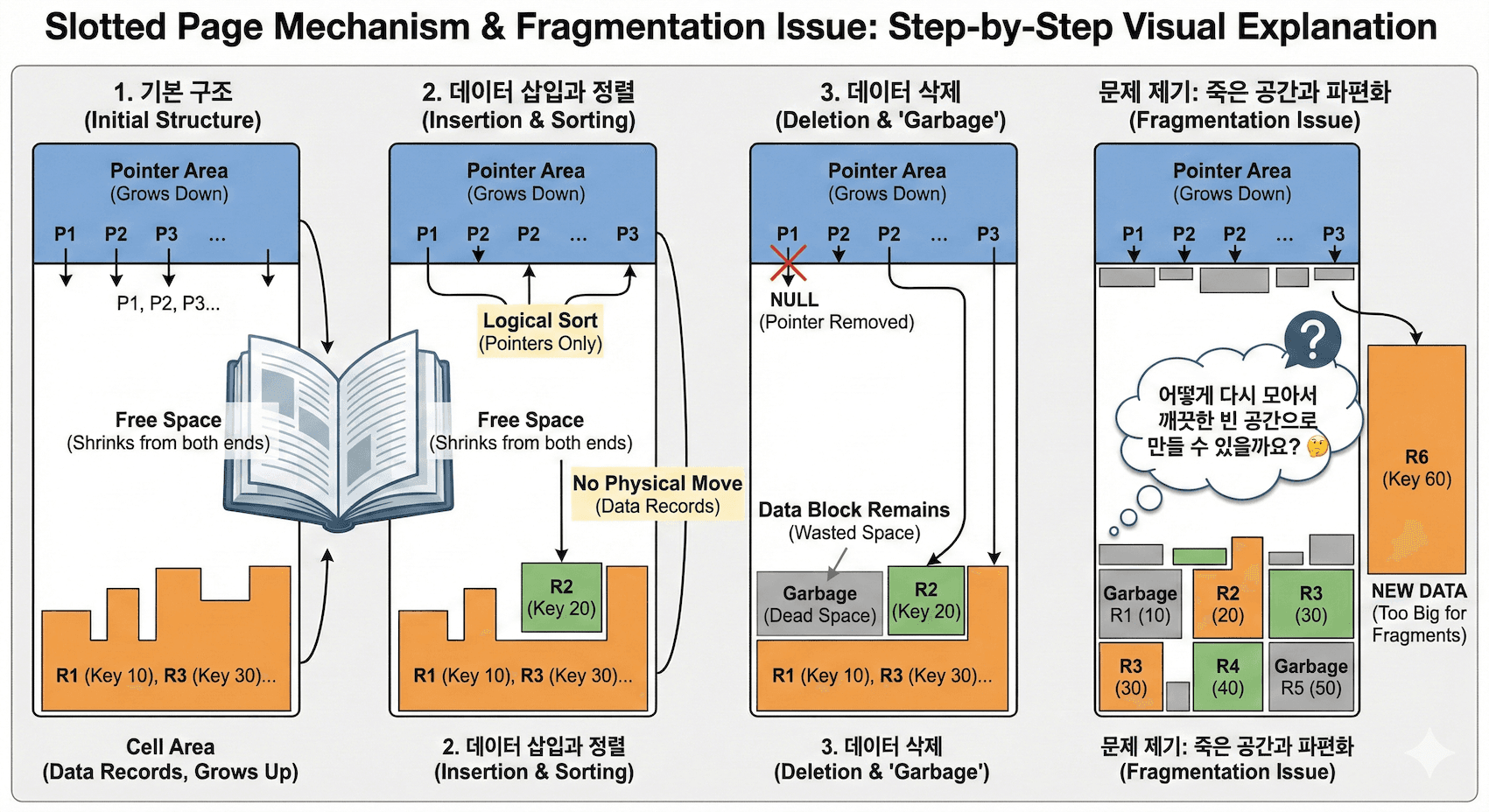
개요
프로그래밍을 하다보면 무언가 읽기 위해 buffer 를 설정할때 꼭 버퍼의 사이즈가 512, 1024, 2048, 4096, … 등으로 올라가는 것을 확인할 수 있다. 왜 이런것일까?
운영체제
하드웨어마다 다르겠지만 보통 하드웨어에서는 섹터(Sector) 단위로 데이터를 읽어온다. 예전 하드웨어에서는 512KB 를 읽어서 로드해주고, 최신 하드웨어에서는 4096KB 크기로 읽어서 올려준다. 즉, 내가 1KB 를 읽던, 2KB 를 읽던 하드웨어는 정해진 섹터 크기만큼 로드해준다는 것이다.
그렇다면 운영체제는 이를 어떻게 받을까? 예전에는 512KB * 8 배를 해서 4096KB 로 오버헤드를 줄이는 방식이였으나, 현대에서는 4096KB 를 그대로 사용하는 것으로 알고 있다. 즉, 4096KB 단위로 관리하므로 이 사이즈에 맞게 읽거나 딱 떨어지게 읽을 수 있다면 편하게 저장하고 읽기 쉽다.
자신의 섹터사이즈가 궁금하다면 아래 커맨드를 입력해서 확인해보면 좋다.
sudo fdisk -l | grep -E "Sector size|I/O size" ─╯
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
블럭 사이즈도 확인해보자 필자는 현재 Ubuntu 25 버전을 이용중이므로 4096 일 것이다.
sudo blockdev --getbsz /dev/sda2
4096
실험
실험에서는 블럭사이즈가 2의 승수 만큼 올라가진 않는 수와 2의 승수로 올라가는 수로 동일한 데이터를 읽었을때 시간차이를 비교해보겠다.
1024KB(Block Size) 씩 20480번 데이터를 읽고 쓰기 = 20971520 bytes (21 MB, 20 MiB)
1130KB(Block Size) 씩 18560번 데이터를 읽고 쓰기 = 20972800 bytes (21 MB, 20 MiB)
위의 데이터를 보면 보통은 2번 케이스가 buffer_size 가 크기 때문에 더 빠르지 않을까? 라는 생각을 할 수 있다. 이걸 테스트 하기 위해 Linux 의 커맨드인 strace 와 dd 를 사용해보겠다.
strace -c dd bs=1130 count=18560 if=/dev/zero of=test1 oflag=direct
일단 인자 설명부터 하겠다.
bs: 블럭사이즈로 예제 2의 경우 1130 으로 설정하면 된다.count: 얼마나 반복해서 옮길것인지 예제 2의 경우 18560 이 된다./dev/zero: 읽을때마다 0을 주는 곳이다.test1:우리가 데이터를 저장할 곳이다.oflag의 direct 는 운영체제의 커널 버퍼를 최대한 이용하지 않고, 하드웨어에 직접 쓰겠다는 의미이다. 커널 버퍼를 이용하게 되면 최적화가 되서 원치 않은 결과가 나오게 될수도 있다.
해당 커맨드를 실행시켜 dd 로 블럭 사이즈를 1130, 그리고 횟수를 18560 으로 잡고 /dev/zero (읽을때 마다 0이 나옴) 에서 데이터를 읽어서 test1 에 파일저장을 해보겠다.
18560+0 records in
18560+0 records out
20972800 bytes (21 MB, 20 MiB) copied, 7.86753 s, 2.7 MB/s
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ------------------
89.88 0.520800 28 18560 write
9.98 0.057836 3 18572 read
0.04 0.000253 23 11 futex
0.02 0.000133 133 1 socketpair
0.02 0.000128 64 2 ftruncate
0.01 0.000045 15 3 clone3
0.01 0.000039 2 18 11 statx
0.01 0.000033 1 17 12 readlink
0.00 0.000024 2 11 close
0.00 0.000022 2 9 rt_sigprocmask
0.00 0.000021 7 3 madvise
0.00 0.000020 0 32 mmap
0.00 0.000014 14 1 sendto
0.00 0.000014 1 12 2 openat
0.00 0.000013 6 2 munmap
0.00 0.000009 0 10 rt_sigaction
0.00 0.000005 1 4 lseek
0.00 0.000004 1 4 brk
0.00 0.000004 4 1 ioctl
0.00 0.000003 1 3 sigaltstack
0.00 0.000000 0 8 fstat
0.00 0.000000 0 1 poll
0.00 0.000000 0 8 mprotect
0.00 0.000000 0 4 pread64
0.00 0.000000 0 2 2 access
0.00 0.000000 0 1 execve
0.00 0.000000 0 2 2 statfs
0.00 0.000000 0 1 arch_prctl
0.00 0.000000 0 1 sched_getaffinity
0.00 0.000000 0 1 set_tid_address
0.00 0.000000 0 1 set_robust_list
0.00 0.000000 0 2 prlimit64
0.00 0.000000 0 2 getrandom
0.00 0.000000 0 1 rseq
------ ----------- ----------- --------- --------- ------------------
100.00 0.579420 15 37311 29 total
약 7.87 초가 소요되었다.
strace -c dd bs=1024 count=20480 if=/dev/zero of=test1 oflag=direct
이제 1024 로 20480 번 시도해보자.
20480+0 records in
20480+0 records out
20971520 bytes (21 MB, 20 MiB) copied, 7.36041 s, 2.8 MB/s
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ------------------
88.91 0.510712 24 20480 write
10.92 0.062707 3 20492 read
0.03 0.000201 15 13 futex
0.03 0.000190 5 32 mmap
0.03 0.000153 153 1 execve
0.01 0.000063 3 17 12 readlink
0.01 0.000056 4 12 2 openat
0.01 0.000055 6 8 mprotect
0.01 0.000049 2 18 11 statx
0.01 0.000045 4 11 close
0.01 0.000031 3 8 fstat
0.01 0.000029 7 4 lseek
0.00 0.000021 2 10 rt_sigaction
0.00 0.000018 9 2 munmap
0.00 0.000018 9 2 ftruncate
0.00 0.000014 3 4 brk
0.00 0.000013 3 4 pread64
0.00 0.000010 3 3 sigaltstack
0.00 0.000009 4 2 2 statfs
0.00 0.000006 3 2 2 access
0.00 0.000006 3 2 prlimit64
0.00 0.000005 0 9 rt_sigprocmask
0.00 0.000005 5 1 sendto
0.00 0.000005 2 2 getrandom
0.00 0.000004 4 1 poll
0.00 0.000004 4 1 arch_prctl
0.00 0.000004 4 1 sched_getaffinity
0.00 0.000003 3 1 set_tid_address
0.00 0.000003 3 1 set_robust_list
0.00 0.000003 3 1 rseq
0.00 0.000002 2 1 ioctl
0.00 0.000000 0 3 madvise
0.00 0.000000 0 1 socketpair
0.00 0.000000 0 3 clone3
------ ----------- ----------- --------- --------- ------------------
100.00 0.574444 13 41153 29 total
약 7.37 초가 소요되었다. 즉, 적은 수의 buffer_size 를 이용함에도 7.87 —> 7.37 초 약 0.5 초가량의 큰 차이가 난다. 데이터가 크다면 기하급수적으로 차이가 더 날것이다.
데이터가 2번 케이스가 더 커서 느린거 아니야?
위와 같은 생각도 할수 있으므로 1024 에서 그냥 더 읽어보겠다.
strace -c dd bs=1024 count=20481 if=/dev/zero of=test1 oflag=direct ─╯
20481+0 records in
20481+0 records out
20972544 bytes (21 MB, 20 MiB) copied, 7.37321 s, 2.8 MB/s
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ------------------
89.04 0.508829 24 20481 write
10.72 0.061252 2 20493 read
0.04 0.000221 22 10 futex
0.03 0.000198 6 32 mmap
0.03 0.000158 158 1 execve
0.02 0.000113 56 2 ftruncate
0.01 0.000071 4 17 12 readlink
0.01 0.000071 5 12 2 openat
0.01 0.000070 3 18 11 statx
0.01 0.000056 7 8 mprotect
0.01 0.000049 4 11 close
0.01 0.000046 46 1 socketpair
0.01 0.000045 15 3 clone3
0.01 0.000035 8 4 lseek
0.01 0.000029 2 10 rt_sigaction
0.00 0.000028 3 9 rt_sigprocmask
0.00 0.000026 3 8 fstat
0.00 0.000022 7 3 madvise
0.00 0.000021 10 2 munmap
0.00 0.000015 3 4 brk
0.00 0.000013 3 4 pread64
0.00 0.000010 5 2 2 statfs
0.00 0.000009 3 3 sigaltstack
0.00 0.000008 4 2 2 access
0.00 0.000006 6 1 sendto
0.00 0.000006 3 2 prlimit64
0.00 0.000006 3 2 getrandom
0.00 0.000004 4 1 poll
0.00 0.000004 4 1 sched_getaffinity
0.00 0.000003 3 1 ioctl
0.00 0.000003 3 1 set_tid_address
0.00 0.000003 3 1 set_robust_list
0.00 0.000003 3 1 rseq
0.00 0.000002 2 1 arch_prctl
------ ----------- ----------- --------- --------- ------------------
100.00 0.571435 13 41152 29 total
데이터를 2번케이스보다도 더 읽고 썼음에도 0.5 초나 더 빠르다. 왜 하드웨어의 섹터 사이즈, 그리고 운영체제의 블록사이즈가 1024, 4096 과 같은 수로 운영되는지 눈으로 확인해볼 수 있었다.