LinkedList 로 DB 를 만들어보자
전시간에는 간단한 파일을 다루는 기본기를 통해 파일을 쓰고, Offset 부터 읽는 등을 학습했다. 이번시간에는 LinkedList 자료구조를 통해 unit32 형태의 값을 저장하고 읽어와보자
인터페이스 정의
type Handle struct {
File *os.File
Header HeaderRecord
}
type HeaderRecord interface {
headerVersion() uint16
}
type LinkedListStore interface {
Open(path string, truncate bool) (*Handle, error)
AppendTail(h *Handle, value uint32) error
DeleteFirstByValue(h *Handle, value uint32) (bool, error)
TraverseValues(h *Handle) ([]uint32, error)
Close(h *Handle) error
}
일단 작업하기에 앞서 필수적인 Interface 들 부터 정의하고 작업을 시작하자. 우리는 LinkedListStore 라는 아래와 같은 연산을 지원하는 저장소를 만들것이다.
AppendTail: 제일 마지막에 value 를 저장하는 연산과DeleteFirstByValue: 첫번째 값을 삭제하는 연산(중복값 저장 가능시)TraverseValues: 그리고 값을 순회하는 연산을 지원한다.
Handle 구조체는 파일을 관리하는 역할을 하며 우리는 앞으로 이 저장소의 Header 를 버저닝하여 업그레이드 할 것이기 때문에 headerVersion() 이라는 함수도 하나 추가해준다.
참고로 지난 시간과 마찬가지로 Endian 은 BigEndian 을 의미한다.
Header 정의
type Header struct {
Magic [4]byte // Magic: 포맷 식별자 [4]byte{'L', 'L', 'S', 'T'}
Version uint16 // Version: 버전
PageSize uint16 // PageSize: 추후에 페이지네이션으로 업그레이드 할때 이용
HeadOffset int64 // HeadOffset: 첫 노드의 파일 오프셋(없으면 -1)
TailOffset int64 // TailOffset: 마지막 노드의 파일 오프셋(없으면 -1)
Size int64 // Size: 통계 / 검증 용도
}
Header 는 우리가 저장한 시스템이 어떻게 이루어져있는지 나타낸다. Version, PageSize 는 지금 챕터에서는 중요하지 않기 때문에 현재 Chapter 에서 중요한 HeadOffset, TailOffset 을 보자.
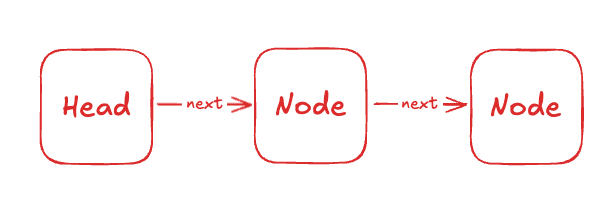
우리가 LinkedList 를 구현할때는 위와 같이 Head 에 대한 정보가 필요하다. 어디서 부터 우리가 순회를 시작해야 할지 알아야 하기 때문에 Head 정보를 알아야 한다. 마찬가지로 우리가 AppendTail 같은 함수를 구현할때는 Head 에서 부터 시작해서 Tail 을 찾는 것보다, Tail 을 항상 관리해서 AppendTail 이 O(1) 시간안에 이뤄지게 하는 것이 낫다.
Node 정의
const nodePadBytes = 3
type Node struct {
Value uint32 // - Value: 실제 값(32비트 정수; 예제 단순화를 위해 uint32 이용)
Next int64 // - Next: 다음 노드의 파일 오프셋 (없으면 -1)
Tomb uint8 // - Tomb: 논리 삭제 마크 (0 == 유효, 1 == 삭제됨). 물리 삭제는 하지 않음
_pad [nodePadBytes]byte // - _pad: 16 바이트 정렬을 위해 3바이트 패딩 (읽기 쉬운 고정 길이 유지)
}
Node 정의는 간단하다. Value 는 우리가 저장할 값인 unit32 를 정의하고 Next 는 다음 노드의 파일 오프셋이 저장될 것이므로 int64 를, Tomb 는 논리 삭제 마크(is_deleted) 로 0 과 1 을 저장한다. _pad 는 Node 를 깔끔하게 16바이트로 저장하기 위해 3byte padding 을 일부러 주었다.
메소드 구현
Header 쓰기
이제 Header 를 쓰는 함수를 먼져 구현해보자. 저번 offset 시간에도 배웠듯이 무언가를 쓰는 경우 해당 값을 쓸만큼의 buffer 를 먼져 생성해주어야 한다. Header 의 경우 4byte+2byte+2byte+8byte+8byte+8byte 로 총 32 바이트가 필요하다.
buf := make([]byte, 0, 32)
이제 이 buffer 에 쓰는 작업은 아주 쉽다.
func writeHeader(f *os.File, hdr *Header) error {
if _, err := f.Seek(0, io.SeekStart); err != nil {
return err
}
buf := make([]byte, 0, 32)
buf = append(buf, hdr.Magic[:]...)
buf = Endian.AppendUint16(buf, hdr.Version)
buf = Endian.AppendUint16(buf, hdr.PageSize)
buf = Endian.AppendUint64(buf, uint64(hdr.HeadOffset))
buf = Endian.AppendUint64(buf, uint64(hdr.TailOffset))
buf = Endian.AppendUint64(buf, uint64(hdr.Size))
_, err := f.Write(buf)
return err
}
buffer 를 생성하고 BigEndian 의 함수를 이용하여 각 byte 크기에 맞게 byte 배열의 마지막에 값을 추가한뒤에 buffer 의 값을 파일에 쓴다.
Header 읽기
func readHeader(f *os.File, h *Header) error {
if _, err := f.Seek(0, io.SeekStart); err != nil {
return err
}
buf := make([]byte, 4+2+2+8+8+8)
if _, err := io.ReadFull(f, buf); err != nil {
return err
}
copy(h.Magic[:], buf[0:4])
// Magic 검증
if h.Magic != Magic {
return ErrInvalidMagic
}
h.Version = Endian.Uint16(buf[4:6])
h.PageSize = Endian.Uint16(buf[6:8])
h.HeadOffset = int64(Endian.Uint64(buf[8:16]))
h.TailOffset = int64(Endian.Uint64(buf[16:24]))
h.Size = int64(Endian.Uint64(buf[24:32]))
return nil
}
Header 를 읽는 과정 또한 쉽다. 우리는 항상 파일의 가장 앞부분에 Header 를 쓸것이기 때문에, Header 크기만큼(32) 읽어온다. 읽어온 뒤에 Uint16 과 같은 함수로 buffer 에서 각 값이 가진 크기에 맞게 byte 배열을 추출하여 원하는 type 으로 변환한다.
이 구현부에서 Header 를 내부에서 생성해서 Return 하는 과정도 좋았을것 같다라는 생각이 들었다.
저장소 열기
이제 Interface 의 함수 중 하나인 Open 을 구현해보자. 우리가 저장소를 열때 원하는 결과는 무엇일까? 바로 우리가 탐색 또는 저장을 위해 필요한 Header 정보를 얻어오는 것이다. 따라서 Handle 의 정보를 얻어와야 할것이므로 아래와 같은 함수일 것이다.
Open(path string, truncate bool) (*Handle, error) // truncate 는 테스트 용으로 시작시 파일을 지우는 용도이다.
그렇다면 이 Open 또한 어렵지 않게 구현해 볼 수 있다.
func (s *OffsetStore) Open(path string, truncate bool) (*Handle, error) {
flags := os.O_RDWR | os.O_CREATE
if truncate {
flags |= os.O_TRUNC
}
f, err := os.OpenFile(path, flags, 0666)
if err != nil {
return nil, err
}
info, err := f.Stat()
if err != nil {
f.Close()
return nil, err
}
if info.Size() == 0 || truncate {
hdr := &Header{
Magic: Magic,
Version: 1,
PageSize: DefaultPageSize,
HeadOffset: NullOffset,
TailOffset: NullOffset,
Size: 0,
}
if err := writeHeader(f, hdr); err != nil {
f.Close()
return nil, err
}
}
hrd := &Header{}
if err := readHeader(f, hrd); err != nil {
f.Close()
return nil, err
}
return &Handle{
File: f,
Header: hrd,
}, nil
}
코드가 복잡해보일수 있는데 생각보다 간단하다. 첫번째 부분은 "파일을 열거나 생성 또는 Truncate" 시키는 부분이다. 그리고 두번째 부분은 만약 "파일을 열었는데 빈 파일이거나, truncate 플래그라면" 우리가 헤더 정보를 넣어야 하므로 Header 를 생성한다. Header 를 생성했다면 기존에 만든 writeHeader 를 통해 파일에 써주면 된다.
만약 이미 값이 있는 데이터베이스라면 위와 같은 행위를 하지 않아도 되므로 readHeader 함수를 통해 Header 를 읽어온다. 이 함수를 통해서 Header 가 없는 경우에는 써주고, 있는 경우에는 읽어와서 Handle 구조체에 Header 와 file 정보를 넣어 리턴해준다.
여기까지는 offset 에 익숙하다면 쉬울 것이다. 만약 익숙하지 않다면 offset 을 읽고 조금 더 이해해보길 바란다. 이제 Node 도 저장하고 읽어와 보자.
Node 쓰고 읽기
const nodeOnDiskSize = 4 + 8 + 1 + nodePadBytes
func writeNodeAt(f *os.File, off int64, n *Node) error {
if _, err := f.Seek(off, io.SeekStart); err != nil {
return err
}
buf := make([]byte, nodeOnDiskSize)
Endian.PutUint32(buf[0:4], uint32(n.Value))
Endian.PutUint64(buf[4:12], uint64(n.Next))
buf[12] = byte(n.Tomb)
if _, err := f.Write(buf); err != nil {
return err
}
return nil
}
func readNodeAt(f *os.File, off int64) (*Node, error) {
if _, err := f.Seek(off, io.SeekStart); err != nil {
return nil, err
}
buf := make([]byte, nodeOnDiskSize)
if _, err := io.ReadFull(f, buf); err != nil {
return nil, err
}
n := &Node{
Value: Endian.Uint32(buf[0:4]),
Next: int64(Endian.Uint64(buf[4:12])),
Tomb: buf[12],
}
return n, nil
}
이제 byte 로 읽고 쓰는 부분은 익숙할테니 한번에 적도록 하겠다. Node 도 마찬가지로 Node 의 크기만큼 buffer 를 생성하고 읽거나 쓴다. 간단하게 설명하면 writeNodeAt 함수는 원하는 위치(offset) 에 Node 를 기록한다. readNodeAt 은 해당 offset 만큼 이동한뒤에 해당 offset 에서부터 nodeSize 만큼 읽어서 buffer 에 저장한다.
아마 익숙할거라 이 부분에 대해서는 더 설명하지는 않겠다. 이제 Node 와 Header 를 읽고 쓰는 부분은 마무리 됬으니 어떻게 Node 를 LinkedList 끝에 옮기는 연산을 계속할지 생각해보자.
AppendTail
AppendTail 을 생각해보면 아래와 같은 알고리즘으로 구현될 것이다.
일단 첫번째로 파일의 처음 부분에서
Header를 읽어온다.새롭게
value를 담은 Node 를 생성한다.파일의 끝 Offset(io.SeekEnd) 에 Node 를 기록한다.
기존 Tail Node 를 읽기 위해 Header 에 기록된 TailOffset 으로 이동해서 Tail Node 를 읽어온다.
기존 TailNode 의 Next 로 새롭게 생성된(newNode) 가리킨다.
기존 Header 의 TailOffset 을 새롭게 생성된 노드의 오프셋으로 바꾼다.
- 만약 과정 도중 Header 가 없는 경우 새롭게 노드를쓴다!
이정도 알고리즘으로 진행이 될 것이다. 코드로 작성해보면 아주 쉽게 확인해 볼 수 있다.
func (s *OffsetStore) AppendTail(handle *Handle, value uint32) error {
h, err := ensureOffsetHeader(handle)
if err != nil {
return err
}
f := handle.File
newNode := &Node{
Value: value,
Next: NullOffset,
Tomb: 0,
}
newOff, err := f.Seek(0, io.SeekEnd)
if err != nil {
return err
}
if err := writeNodeAt(f, newOff, newNode); err != nil {
return err
}
if h.HeadOffset == NullOffset {
h.HeadOffset = newOff
h.TailOffset = newOff
h.Size++
return writeHeader(f, h)
}
// 기존 tail 노드의 Next 를 새 노드의 Next 로 설정
tailNode, err := readNodeAt(f, h.TailOffset)
if err != nil {
return err
}
tailNode.Next = newOff
if err := writeNodeAt(f, h.TailOffset, tailNode); err != nil {
return err
}
h.TailOffset = newOff
h.Size++
return writeHeader(f, h)
}
아마 알고리즘을 먼져익히고 코드를 보면 이해가 쉽게 갈 것이다. 그렇다면 탐색은 어떨까? 탐색도 동일하다.
func (s *OffsetStore) TraverseValues(handle *Handle) ([]uint32, error) {
h, err := ensureOffsetHeader(handle)
if err != nil {
return nil, err
}
f := handle.File
out := make([]uint32, 0, h.Size)
off := h.HeadOffset
for off != NullOffset {
node, err := readNodeAt(f, off)
if err != nil {
return nil, err
}
if node.Tomb == 0 {
out = append(out, node.Value)
}
off = node.Next
}
return out, nil
}
파일을 열고 Header 에서 HeadOffset 을 읽어온 뒤에 NullOffset 에 도달할때까지 순회를 계속하며 Next Offset 으로 이동하며 Node 들을 읽어온다. (단. Tomb == 1 죽은 노드들은 제외한다.)
여기서 값을 찾는다면?
만약이 LinkedListStore 에서 특정 값을 찾는다면 시간복잡도가 얼마나 소비될까? LinkedList 의 복잡도인 O(N) 만큼 소비될 것이다. 왜냐면, Header 로 부터 시작해서 Next 들을 순회하며 마지막 노드까지 도달할 수 있기 때문이다. 코드는 간단하게 아래와 같이 작성해 볼수 있을 것이다.
func (s *OffsetStore) Where(handle *Handle, target uint32) (int64, error) {
h, err := ensureOffsetHeader(handle)
if err != nil {
return 0, err
}
f := handle.File
off := h.HeadOffset
for off != NullOffset {
node, err := readNodeAt(f, off)
if err != nil {
return 0, err
}
if node.Tomb == 0 && node.Value == target {
return off, nil
}
off = node.Next
}
return NullOffset, nil
}
여기서 또 하나의 문제가 생긴다. O(N) 의 시간복잡도가 드는것도 문제지만 사실 파일을 읽는 I/O 작업은 상당히 헤비한 작업이다. 이 파일을 읽는 작업또한 오래걸릴 수 있다는 것이다. 여기서 어떻게 조금 더 최적화 해볼수 있을까?
떠오르는 방법으로는 만약 정렬된 순서라면 1~5 까지 노드의 HeadOffset 과 TailOffset 을 저장하고, 5~10, 10~15까지를 메모리에 Key-Value 상태로 인덱싱하고, 해당 Value 는 Offset 이므로 해당 그룹에서만 순회를 진행하는 것이다. 그렇게 되면 전체 크기에서 격자로 나눈 만큼이 M 이라면 O(N/M) 의 평균 시간복잡도로 변할것이고, 파일 I/O 또한 줄게된다.
이러한 방식을 생각하다보면 결국 Node 를 묶어서 관리하고 해당 그룹의 Offset 을 관리해야겠다는 생각이 든다. 따라서 다음 글에서는 이를 Page 라는 단위로 묶고, Node 는 Page 하부의 Slot 으로 관리하여 File I/O 를 줄이고, 메모리에서 순회하여 I/O 자체를 줄여보는 최적화를 진행해보겠다.