PostgreSQL SharedBuffer Hashtable, Hashfunction 구성 직접 알아보기
PostgreSQL ShareBuffer
웹 서버를 운영하거나 데이터베이스를 운용하게 되는 경우 최종적으로 물리적인 위치에 가는 것보다, 최대한 홉을 줄이는 등의 I/O 를 최소화하기 위한 방법들이 주로 이용된다. PostgreSQL 의 SharedBuffer 도 마찬가지로 물리적인 위치에 도달하여 Disk 에 I/O 를 일으키는 것보다 앞단의 Buffer 에 있으면 그값을 읽고 리턴하여 I/O 를 최소화 해주는 장치다.
Shared Buffer
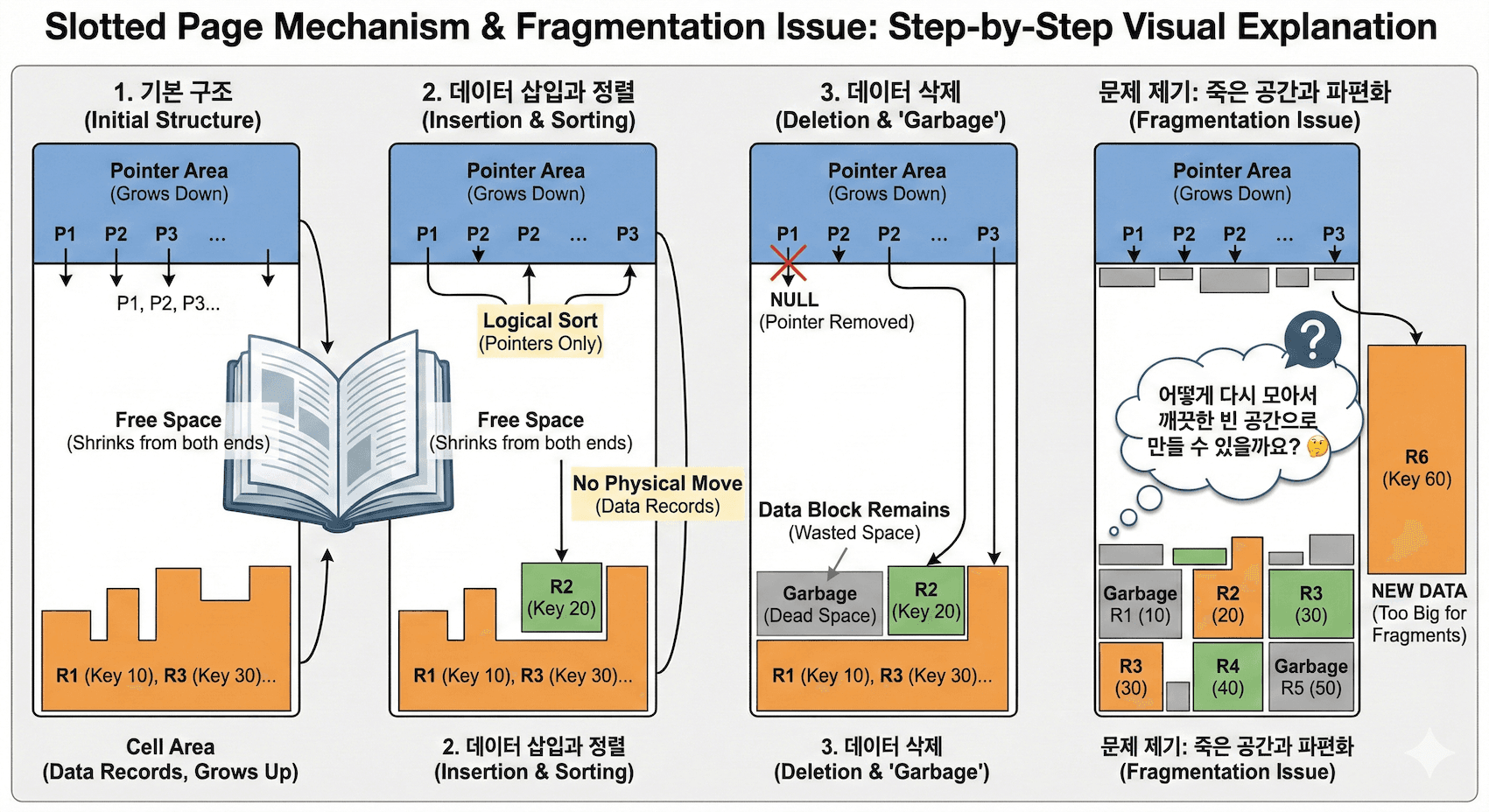
SharedBuffer 는 기본적으로 Hash Table, Hash function, Buffer Descriptor, Buffer pool 로 되어있다. 오늘은 이 HashTable 과 Hash function 에 대해 직접 테이블을 만들고, 쿼리를 날려보며 어떻게 Hash Table 에 적재되는지 테스트 해보려고 한다. (이글은 SharedBuffer 의 존재에 대해 어느정도 알고있다고 가정하고 핸즈온 느낌으로 적어보려고 한다)
Hash function
/*
* BufTableHashCode
* Compute the hash code associated with a BufferTag
*
* This must be passed to the lookup/insert/delete routines along with the
* tag. We do it like this because the callers need to know the hash code
* in order to determine which buffer partition to lock, and we don't want
* to do the hash computation twice (hash_any is a bit slow).
*/
uint32
BufTableHashCode(BufferTag *tagPtr)
{
return get_hash_value(SharedBufHash, tagPtr);
}
hash function 은 기본적으로 Shared Buffers 에 있는 hash_table 에서 원하는 값을 가져오기 위한 key 값을 계산하기 위해 사용된다. 언어에 내장된 HashMap 같은 것을 공부하다 보면 보통 최소한으로 Lock 을 잡기 위해 Partioning 을 진행하고, 해당 파티션에만 락을 수행하게 되는데 PG 도 버전이 업그레이드 되면서 아래 처럼hash function 을 통해 필요한 영역에만 Lock 을 잡도록 되어 있다.
static inline LWLock *
BufMappingPartitionLock(uint32 hashcode)
{
return &MainLWLockArray[BUFFER_MAPPING_LWLOCK_OFFSET +
BufTableHashPartition(hashcode)].lock;
}
그런데 처음으로 BufTableHashCode 함수를 보면 BufferTag 기반으로 hash key 값을 계산하는 것을 확인할 수 있다. BufferTag 는 무엇이고, 어떤 데이터길래 hash 함수 계산에 이용될까?
BufferTag
/*
* Buffer tag identifies which disk block the buffer contains.
*
* Note: the BufferTag data must be sufficient to determine where to write the
* block, without reference to pg_class or pg_tablespace entries. It's
* possible that the backend flushing the buffer doesn't even believe the
* relation is visible yet (its xact may have started before the xact that
* created the rel). The storage manager must be able to cope anyway.
*
* Note: if there's any pad bytes in the struct, InitBufferTag will have
* to be fixed to zero them, since this struct is used as a hash key.
*/
typedef struct buftag
{
Oid spcOid; /* tablespace oid */
Oid dbOid; /* database oid */
RelFileNumber relNumber; /* relation file number */
ForkNumber forkNum; /* fork number */
BlockNumber blockNum; /* blknum relative to begin of reln */
} BufferTag;
설명하기 전에 소스코드를 먼져 보고 들어가면 buftag(BufferTag) 라는 구조체는 위와 같이 파일의 실제 위치정보를 가지고 있음을 확인할 수 있다. 위 주석에도 나와있다. "Buffer tag identifies which disk block the buffer contains the BufferTag data must be sufficient to determine where to write the block". 즉, BufferTag 를 통해서 데이터의 물리적인 File 위치를 알 수 있는 것이다.
조금만 더 쉽게 예시를 들어보자. 만약 유저가 SELECT * FROM users WHERE id = 1000; 이라는 쿼리를 날렸다고 해보자. 이 users 라는 테이블은 pg_default 스페이스에 그리고, myapp 이라는 db 에 있다고 해보겠다. 그렇다면 BufferTag 는 아래와 같이 구성될 것이다.
BufferTag tag = {
.spcOid = 1663, // pg_default 테이블스페이스
.dbOid = 16385, // myapp 데이터베이스
.relNumber = 16390, // users 테이블
.forkNum = 0, // 메인 데이터 파일
.blockNum = 100 // 101번째 페이지 (0부터 시작)
};
그리고 BufferTag 기반으로 해시키를 생성할 것이다.
uint32 hash = BufTableHashCode(&tag);
이렇게 생성된 hash 값을 통해 우리는 HashTable 에 값이 있는지 없는지 Lookup 해볼수 있다.
buffer_id = BufTableLookup(&tag, hash);
if (buffer_id >= 0) {
// 있을 경우 바로 메모리에서 읽기
} else {
// 없을 경우 실제 물리적인 위치로 이동해서 데이터 가져오기
}
실제로 테스트 해보기
일단 실습을 진행하기 위해서 postgreSQL 에 접속해준다.
postgres=# SELECT current_database();
그리고 일반적으로 pg 의 buffer 사용량을 체크하기 위해 주로 이용되는 pg_buffercache extension 을 설치해줘야 한다.
CREATE EXTENSION IF NOT EXISTS pg_buffercache;
이제 테스트를 위한 테이블을 하나 추가해보자.
postgres=# CREATE TABLE test_buffer AS
postgres-# SELECT generate_series(1, 1000) as id,
postgres-# 'data_' || generate_series(1, 1000) as name;
테이블을 추가하고 난 뒤에는 이제 BufferCache 에 잘 올라갔는지 확인해보아야 한다. 일단 전체 테이블을 조회하고 난뒤에 BufferCache 를 확인해보자.
postgres=# SELECT count(*) FROM test_buffer;
count
-------
1000
(1 row)
postgres=# SELECT count(*) FROM pg_buffercache WHERE relfilenode = (SELECT oid FROM pg_class WHERE relname = 'test_buffer');
count
-------
8
(1 row)
우리가 넣은 1000건이 잘 조회되었다. 그런데 BufferCache 를 보면 8건만 올라와있는 것을 확인할 수 있다. 아마 페이지에 저장되었기때문에 8개로 나오는 것이겠지만 실제로 한번 쿼리를 통해 확인해보도록 하자.
SELECT
bufferid,
relfilenode,
reltablespace,
reldatabase,
relforknumber,
relblocknumber,
isdirty,
usagecount
FROM pg_buffercache
WHERE relfilenode = (SELECT oid FROM pg_class WHERE relname = 'test_buffer')
ORDER BY relblocknumber;
bufferid | relfilenode | reltablespace | reldatabase | relforknumber | relblocknumber | isdirty | usagecount
----------+-------------+---------------+-------------+---------------+----------------+---------+------------
247 | 24585 | 1663 | 5 | 0 | 0 | t | 2
248 | 24585 | 1663 | 5 | 0 | 1 | t | 2
249 | 24585 | 1663 | 5 | 0 | 2 | t | 2
250 | 24585 | 1663 | 5 | 0 | 3 | t | 2
251 | 24585 | 1663 | 5 | 0 | 4 | t | 2
252 | 24585 | 1663 | 5 | 0 | 5 | t | 2
253 | 24585 | 1663 | 5 | 0 | 6 | f | 2
254 | 24585 | 1663 | 5 | 0 | 7 | f | 2
(8 rows)
결과를 보면 relblocknumber 가 0~7까지 인것을 확인할 수 있다. 즉 릴레이션 안의 페이지수가 8개인 것이다. 실제로 페이지에 값이 어떻게 되어 있는지도 PostgreSQL pageinspect extension 을 통해 확인 가능하다. 한번 설치해보도록 하자.
CREATE EXTENSION IF NOT EXISTS pageinspect;
이제 원하는 page block 내부에 튜플 정보를 확인해보기 위해서 heap_page_items 과 get_raw_page 라는 함수를 이용할 것이다.
SELECT
lp as item_number,
lp_off as offset,
lp_len as length,
t_ctid
FROM heap_page_items(get_raw_page('test_buffer', 0));
item_number | offset | length | t_ctid
-------------+--------+--------+---------
1 | 8152 | 35 | (0,1)
2 | 8112 | 35 | (0,2)
3 | 8072 | 35 | (0,3)
4 | 8032 | 35 | (0,4)
5 | 7992 | 35 | (0,5)
6 | 7952 | 35 | (0,6)
7 | 7912 | 35 | (0,7)
8 | 7872 | 35 | (0,8)
9 | 7832 | 35 | (0,9)
10 | 7792 | 36 | (0,10)
확인해보면 결과가 위와 같은 것을 확인할 수 있다. 다른 것들은 일단 스킵하고 t_ctid 를 일단 보면 된다. t_ctid 는 (페이지 블럭번호, 아이템번호) 로 구성되어 있으며 이건 행의 물리적 주소를 나타낸다.
A word about t_ctid: whenever a new tuple is stored on disk, its t_ctid is initialized with its own TID (location).
즉, 우리가 만들었던 데이터(SELECT generate_series(1, 1000) as id, 'data_' || generate_series(1, 1000) as name;) 를 확인하기 위해서는 아래와 같이 id 와 name 값을 조회하면 확인해볼수있다.
SELECT
ctid, -- 물리적 위치
id, -- 실제 데이터
name -- 실제 데이터
FROM test_buffer
WHERE ctid = '(0,1)'
ctid | id | name
-------+----+--------
(0,1) | 1 | data_1
(1 row)
결과 또한 잘 나오는걸 확인해볼수 있다.
결론
BufferCache 에는 raw 단위가 아닌 페이지단위로 저장된다. 즉, 해당 페이지에서 부터는 O(N) 으로 접근하게 될 것이다.