Umap 파헤치기
테디노트의 랭체인을 활용한 RAG 비법노트 심화편을 보다가 UMAP 알고리즘을 마주하게 됬다. 더 높은 차원의 벡터를 낮은 차원으로서 차원축소를 하는 개념인데 이 알고리즘이 어떻게 차원을 축소하는건지 이해가 가지 않아서 해당 개념을 찾아 정리해보았다.
예시로 알아보기
일단 UMAP 에 대해서 이해하기 위해서는 눈으로 볼수 있는 데이터가 어느정도 필요하다. 만약 아래와 같은 [로맨스, 스릴러, 코미디, 판타지, 교양] 의 특성을 나타내는 벡터가 있다고 가정해보자. 그리고 해당 아래와 같이 “책 또는 장르” 를 기준으로 해당 특성에 대한 값을 커스텀하게 나타내 보겠다.
books = {
# 그룹 1: 판타지/모험
"해리포터": [2, 7, 5, 10, 3],
"반지의 제왕": [1, 8, 2, 9, 1],
# 그룹 2: 로맨스/코미디
"로맨틱 코미디": [10, 1, 8, 1, 1],
"순정 로맨스": [9, 2, 3, 2, 1],
# 그룹 3: 교양/다큐
"과학 교양서": [0, 1, 1, 0, 10],
"역사 다큐": [0, 3, 1, 1, 8]
}
조금 벡터에 친숙하지 않은 사람들은 어렵겠지만 쉽게 생각하면 엑셀표처럼 보면 된다. 각 열(column)이 특성에 대한 수치를 나타낸다. 보면 알겠듯이, 이 벡터는 현재는 5차원의 정보를 지니고 있다. 만약 우리가 이 벡터를 2차원으로 축소해야 한다면 어떻게 해야할까?
나이브하게 접근해본다면 여기서 두가지 특성만 뽑아볼수 있겠다. 예시로 “코미디”, “로맨스” 특성을 이용해서 2차원으로 축소해본다고 해보자. (나머지 값은 지우는 것으로 가정하겠다)

해당 두차원으로 축소하게 되면 누가봐도 뭔가 이상하다는것을 느낄수 있다. “해리포터” 와 “반지의 제왕” 이 느낌상 가까워야 할것 같지만 상당히 먼곳에 분포해있음을 알수 있다. 그리고 “과학 교양서” 와 “역사 다큐” 는 거의 겹쳐져 있는 수준으로 가깝다. 즉, 다른 차원을 무시하고(정보 손실) 두개의 차원만 이용하는 것은 상당히 원본 차원을 무시하고 배치하고 있음을 나타낼수 있다.
UMAP
UMAP 은 이러한 고민을 해결하는 방법중 한가지이다. 즉, 어떻게 하면 원본의 정보를 최대한 소실하지 않고 차원을 축소하는가에 대한 고민이 UMAP 에 녹아들어 있다. 이 아티클은 쉽게 푸는것이 목적이므로 수학적으로 깊이 들어가지는 않겠다. 사실 들어갈 실력도 딱히 안되므로, 근본적인 핵심 아이디어를 적어보자면 “A 기준으로 B 를 이웃으로 볼 확률” 을 기준으로 “고차원이든 저차원이든 최대한 비슷한 확률을 보존하도록” 차원을 축소해 나가는 것이다.
예를 들어, 우리의 예시에서 원본(5차원)차원 기준으로 “해리포터와 반지의 제왕” 의 유사도를 비교해보자.
# 두 점 사이의 거리를 계산하는 함수
def euclidean_distance(p1, p2):
return np.sqrt(np.sum((p1 - p2)**2))
# 거리를 유사도 점수(0~1)로 변환하는 간단한 함수 (가까울수록 1에 가까워짐)
def distance_to_similarity(distance, sigma=1.0):
return np.exp(- (distance**2) / (2 * sigma**2))
# 1. 고차원(5D)에서의 유사도 계산
hp_5d = book_data[0]
lotr_5d = book_data[1]
distance_5d = euclidean_distance(hp_5d, lotr_5d)
similarity_5d = distance_to_similarity(distance_5d, sigma=5.0)
print(f"[5차원] '해리포터'와 '반지의 제왕'의 관계")
print(f" - 유클리드 거리: {distance_5d:.2f}") # 4.00
print(f" - 유사도 점수: {similarity_5d:.3f}") # 0.726
실제로 계산해보면 “유클리드 거리” 는 4.00 이고 유사도는 0.726 으로 나옴을 확인해볼 수 있다. 그렇다면 차원을 2차원으로 축소하고 나서는 얼마나 보존될까? umap 을 이용해서 축소하고 나서 유사도를 비교해보자.
reducer = umap.UMAP(n_neighbors=2, min_dist=0.5, random_state=42)
embedding = reducer.fit_transform(book_data)
# 2. 저차원(2D)에서의 유사도 계산
hp_2d = embedding[0]
lotr_2d = embedding[1]
distance_2d = euclidean_distance(hp_2d, lotr_2d)
similarity_2d = distance_to_similarity(distance_2d, sigma=1.0) # 2D 공간 스케일에 맞게 sigma 조정
print(f"[2차원] UMAP 실행 후 '해리포터'와 '반지의 제왕'의 관계")
print(f" - 유클리드 거리: {distance_2d:.2f}")
print(f" - 유사도 점수: {similarity_2d:.3f}")
print("\n 비교 결과:")
print(f" - 5차원 유사도: {similarity_5d:.3f}")
print(f" - 2차원 유사도: {similarity_2d:.3f}")
[2차원] UMAP 실행 후 '해리포터'와 '반지의 제왕'의 관계
- 유클리드 거리: 0.93
- 유사도 점수: 0.651
비교 결과:
- 5D 유사도: 0.726
- 2D 유사도: 0.651
즉, UMAP 이 약간의 손실은 있지만 거의 정보를 잘 보존했음을 확인할 수 있다. 값으로만 보면 유사하다고 못 느낄수도 있으니 실제 그래프로 한번 확인해보자.
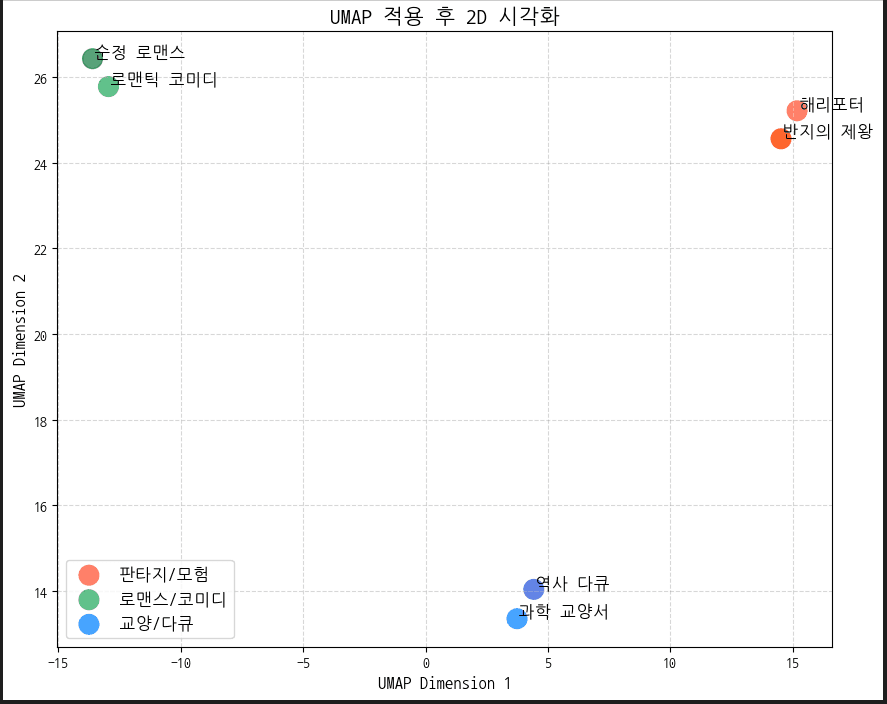
그래프로 확인

눈으로 보면 알수 있듯이 실제로 정보를 잘 보존한채 차원이 잘 축소됬음을 확인할 수 있다. 수학적으로 조금 더 깊게 들어가면 딥해지는것 같은데 일단은 RAG 비법노트의 심화편을 읽기에는 이정도의 이해도로도 괜찮은거 같다. 나중에 조금 더 파라미터 부분을 건드릴때 딥하게 들어가봐야겠다.